This repository has no description
first commit
author
damedotblog
date
(Mar 7, 2025, 4:59 PM -0500)
commit
bbbd0efd
bbbd0efdc027a8f80ec89cfae0fa17b697411d07
+3342
.DS_Store
.DS_Store
This is a binary file and will not be displayed.
+61
app/README.md
+61
app/README.md
···
1
+
# I'm Flushing
2
+
3
+
A React/Next.js application that allows users to login with their Bluesky account and set a status update with a custom lexicon schema called `im.flushing.right.now`.
4
+
5
+
## Features
6
+
7
+
- Bluesky OAuth authentication
8
+
- Custom lexicon schema for status updates
9
+
- Emoji selection
10
+
- Responsive design
11
+
12
+
## Tech Stack
13
+
14
+
- Next.js
15
+
- React
16
+
- TypeScript
17
+
- Bluesky AT Protocol
18
+
19
+
## Local Development
20
+
21
+
1. Clone the repository
22
+
2. Install dependencies:
23
+
24
+
```bash
25
+
npm install
26
+
```
27
+
28
+
3. Start the development server:
29
+
30
+
```bash
31
+
npm run dev
32
+
```
33
+
34
+
4. Open [http://localhost:3000](http://localhost:3000) in your browser
35
+
36
+
## Deployment
37
+
38
+
This application is designed to be deployed on Vercel with the domain `flushing.im`.
39
+
40
+
For production deployment:
41
+
42
+
1. Update the OAuth redirect URLs in both code and the Bluesky developer settings
43
+
2. Make sure the client metadata file is accessible at `https://flushing.im/client-metadata.json`
44
+
3. Deploy the application to Vercel
45
+
46
+
## Custom Lexicon Schema
47
+
48
+
This application uses a custom lexicon schema called `im.flushing.right.now` with the following structure:
49
+
50
+
```json
51
+
{
52
+
"$type": "im.flushing.right.now",
53
+
"text": "String - The status text",
54
+
"emoji": "String - A single emoji character",
55
+
"createdAt": "String - ISO timestamp"
56
+
}
57
+
```
58
+
59
+
## License
60
+
61
+
MIT
+5
app/next-env.d.ts
+5
app/next-env.d.ts
+9
app/next.config.js
+9
app/next.config.js
+23
app/package.json
+23
app/package.json
···
1
+
{
2
+
"name": "im-flushing",
3
+
"version": "0.1.0",
4
+
"private": true,
5
+
"scripts": {
6
+
"dev": "next dev",
7
+
"build": "next build",
8
+
"start": "next start",
9
+
"lint": "next lint"
10
+
},
11
+
"dependencies": {
12
+
"next": "^14.1.0",
13
+
"react": "^18.2.0",
14
+
"react-dom": "^18.2.0",
15
+
"@atproto/api": "^0.12.0"
16
+
},
17
+
"devDependencies": {
18
+
"@types/node": "^20.10.5",
19
+
"@types/react": "^18.2.45",
20
+
"@types/react-dom": "^18.2.18",
21
+
"typescript": "^5.3.3"
22
+
}
23
+
}
+22
app/public/client-metadata.json
+22
app/public/client-metadata.json
···
1
+
{
2
+
"client_id": "https://flushing.im/client-metadata.json",
3
+
"application_type": "web",
4
+
"client_name": "I'm Flushing",
5
+
"client_uri": "https://flushing.im",
6
+
"logo_uri": "https://flushing.im/logo.png",
7
+
"tos_uri": "https://flushing.im/terms",
8
+
"policy_uri": "https://flushing.im/privacy",
9
+
"dpop_bound_access_tokens": true,
10
+
"grant_types": [
11
+
"authorization_code",
12
+
"refresh_token"
13
+
],
14
+
"redirect_uris": [
15
+
"https://flushing.im/auth/callback"
16
+
],
17
+
"response_types": [
18
+
"code"
19
+
],
20
+
"scope": "atproto transition:generic",
21
+
"token_endpoint_auth_method": "none"
22
+
}
+44
app/src/app/auth/callback/callback.module.css
+44
app/src/app/auth/callback/callback.module.css
···
1
+
.container {
2
+
display: flex;
3
+
flex-direction: column;
4
+
align-items: center;
5
+
justify-content: center;
6
+
min-height: 70vh;
7
+
padding: 2rem;
8
+
}
9
+
10
+
.loaderContainer, .errorContainer {
11
+
text-align: center;
12
+
max-width: 500px;
13
+
}
14
+
15
+
.loader {
16
+
border: 5px solid #f3f3f3;
17
+
border-top: 5px solid var(--primary-color);
18
+
border-radius: 50%;
19
+
width: 50px;
20
+
height: 50px;
21
+
animation: spin 1s linear infinite;
22
+
margin: 0 auto 20px;
23
+
}
24
+
25
+
@keyframes spin {
26
+
0% { transform: rotate(0deg); }
27
+
100% { transform: rotate(360deg); }
28
+
}
29
+
30
+
.error {
31
+
color: var(--error-color);
32
+
margin: 1rem 0;
33
+
word-break: break-word;
34
+
}
35
+
36
+
.button {
37
+
margin-top: 1rem;
38
+
background-color: var(--primary-color);
39
+
color: white;
40
+
border: none;
41
+
border-radius: 4px;
42
+
padding: 0.5rem 1rem;
43
+
cursor: pointer;
44
+
}
+137
app/src/app/auth/callback/page.tsx
+137
app/src/app/auth/callback/page.tsx
···
1
+
'use client';
2
+
3
+
import { useEffect, useState } from 'react';
4
+
import { useRouter, useSearchParams } from 'next/navigation';
5
+
import { getAccessToken } from '@/lib/bluesky-auth';
6
+
import { getProfile } from '@/lib/bluesky-api';
7
+
import { useAuth } from '@/lib/auth-context';
8
+
import styles from './callback.module.css';
9
+
10
+
export default function CallbackPage() {
11
+
const router = useRouter();
12
+
const searchParams = useSearchParams();
13
+
const { setAuth } = useAuth();
14
+
const [error, setError] = useState<string | null>(null);
15
+
const [status, setStatus] = useState('Processing login...');
16
+
17
+
useEffect(() => {
18
+
async function handleCallback() {
19
+
try {
20
+
// Get parameters from URL
21
+
const code = searchParams.get('code');
22
+
const state = searchParams.get('state');
23
+
const iss = searchParams.get('iss');
24
+
25
+
if (!code || !state || !iss) {
26
+
setError('Invalid callback parameters');
27
+
return;
28
+
}
29
+
30
+
// Get stored values from session storage
31
+
const storedState = sessionStorage.getItem('oauth_state');
32
+
const codeVerifier = sessionStorage.getItem('code_verifier');
33
+
const serializedKeyPair = sessionStorage.getItem('key_pair');
34
+
35
+
// Validate state
36
+
if (state !== storedState) {
37
+
setError('Invalid state parameter');
38
+
return;
39
+
}
40
+
41
+
if (!codeVerifier || !serializedKeyPair) {
42
+
setError('Missing authorization data');
43
+
return;
44
+
}
45
+
46
+
setStatus('Exchanging authorization code...');
47
+
48
+
// Deserialize key pair
49
+
const keyPairData = JSON.parse(serializedKeyPair);
50
+
const publicKey = await window.crypto.subtle.importKey(
51
+
'jwk',
52
+
keyPairData.publicKey,
53
+
{ name: 'ECDSA', namedCurve: 'P-256' },
54
+
true,
55
+
['verify']
56
+
);
57
+
const privateKey = await window.crypto.subtle.importKey(
58
+
'jwk',
59
+
keyPairData.privateKey,
60
+
{ name: 'ECDSA', namedCurve: 'P-256' },
61
+
true,
62
+
['sign']
63
+
);
64
+
const keyPair = { publicKey, privateKey };
65
+
66
+
// Exchange code for tokens
67
+
const tokenResponse = await getAccessToken(code, codeVerifier, keyPair);
68
+
69
+
if (!tokenResponse.access_token || !tokenResponse.refresh_token) {
70
+
setError('Failed to get access token');
71
+
return;
72
+
}
73
+
74
+
setStatus('Getting user profile...');
75
+
76
+
// Get user profile
77
+
const profileResponse = await getProfile(
78
+
tokenResponse.access_token,
79
+
keyPair,
80
+
null
81
+
);
82
+
83
+
// Serialize key pair for storage
84
+
const serializedKeysForStorage = JSON.stringify({
85
+
publicKey: keyPairData.publicKey,
86
+
privateKey: keyPairData.privateKey
87
+
});
88
+
89
+
// Store auth data
90
+
setAuth({
91
+
accessToken: tokenResponse.access_token,
92
+
refreshToken: tokenResponse.refresh_token,
93
+
did: tokenResponse.sub,
94
+
handle: profileResponse?.handle || 'unknown',
95
+
serializedKeyPair: serializedKeysForStorage,
96
+
dpopNonce: null
97
+
});
98
+
99
+
// Clear session storage
100
+
sessionStorage.removeItem('oauth_state');
101
+
sessionStorage.removeItem('code_verifier');
102
+
sessionStorage.removeItem('key_pair');
103
+
104
+
// Redirect to dashboard
105
+
router.push('/dashboard');
106
+
} catch (err: any) {
107
+
console.error('Login callback error:', err);
108
+
setError(`Login failed: ${err.message || 'Unknown error'}`);
109
+
}
110
+
}
111
+
112
+
handleCallback();
113
+
}, [searchParams, router, setAuth]);
114
+
115
+
if (error) {
116
+
return (
117
+
<div className={styles.container}>
118
+
<div className={styles.errorContainer}>
119
+
<h1>Authentication Error</h1>
120
+
<p className={styles.error}>{error}</p>
121
+
<button onClick={() => router.push('/')} className={styles.button}>
122
+
Back to Home
123
+
</button>
124
+
</div>
125
+
</div>
126
+
);
127
+
}
128
+
129
+
return (
130
+
<div className={styles.container}>
131
+
<div className={styles.loaderContainer}>
132
+
<div className={styles.loader}></div>
133
+
<p>{status}</p>
134
+
</div>
135
+
</div>
136
+
);
137
+
}
+36
app/src/app/auth/login/login.module.css
+36
app/src/app/auth/login/login.module.css
···
1
+
.container {
2
+
display: flex;
3
+
flex-direction: column;
4
+
align-items: center;
5
+
justify-content: center;
6
+
min-height: 70vh;
7
+
padding: 2rem;
8
+
}
9
+
10
+
.loaderContainer, .errorContainer {
11
+
text-align: center;
12
+
}
13
+
14
+
.loader {
15
+
border: 5px solid #f3f3f3;
16
+
border-top: 5px solid var(--primary-color);
17
+
border-radius: 50%;
18
+
width: 50px;
19
+
height: 50px;
20
+
animation: spin 1s linear infinite;
21
+
margin: 0 auto 20px;
22
+
}
23
+
24
+
@keyframes spin {
25
+
0% { transform: rotate(0deg); }
26
+
100% { transform: rotate(360deg); }
27
+
}
28
+
29
+
.error {
30
+
color: var(--error-color);
31
+
margin: 1rem 0;
32
+
}
33
+
34
+
.backButton {
35
+
margin-top: 1rem;
36
+
}
+63
app/src/app/auth/login/page.tsx
+63
app/src/app/auth/login/page.tsx
···
1
+
'use client';
2
+
3
+
import { useEffect, useState } from 'react';
4
+
import { useRouter } from 'next/navigation';
5
+
import { getAuthorizationUrl } from '@/lib/bluesky-auth';
6
+
import styles from './login.module.css';
7
+
8
+
export default function LoginPage() {
9
+
const router = useRouter();
10
+
const [error, setError] = useState<string | null>(null);
11
+
const [isLoading, setIsLoading] = useState(true);
12
+
13
+
useEffect(() => {
14
+
async function initiateLogin() {
15
+
try {
16
+
// Get authorization URL
17
+
const { url, state, codeVerifier, keyPair } = await getAuthorizationUrl();
18
+
19
+
// Store auth state in sessionStorage
20
+
sessionStorage.setItem('oauth_state', state);
21
+
sessionStorage.setItem('code_verifier', codeVerifier);
22
+
23
+
// Serialize and store keyPair
24
+
const publicJwk = await window.crypto.subtle.exportKey('jwk', keyPair.publicKey);
25
+
const privateJwk = await window.crypto.subtle.exportKey('jwk', keyPair.privateKey);
26
+
const serializedKeyPair = JSON.stringify({ publicKey: publicJwk, privateKey: privateJwk });
27
+
sessionStorage.setItem('key_pair', serializedKeyPair);
28
+
29
+
// Redirect to Bluesky login
30
+
window.location.href = url;
31
+
} catch (err) {
32
+
console.error('Failed to initiate login:', err);
33
+
setError('Failed to initiate login. Please try again.');
34
+
setIsLoading(false);
35
+
}
36
+
}
37
+
38
+
initiateLogin();
39
+
}, []);
40
+
41
+
if (error) {
42
+
return (
43
+
<div className={styles.container}>
44
+
<div className={styles.errorContainer}>
45
+
<h1>Login Error</h1>
46
+
<p className={styles.error}>{error}</p>
47
+
<button onClick={() => router.push('/')} className={styles.backButton}>
48
+
Back to Home
49
+
</button>
50
+
</div>
51
+
</div>
52
+
);
53
+
}
54
+
55
+
return (
56
+
<div className={styles.container}>
57
+
<div className={styles.loaderContainer}>
58
+
<div className={styles.loader}></div>
59
+
<p>Redirecting to Bluesky login...</p>
60
+
</div>
61
+
</div>
62
+
);
63
+
}
+193
app/src/app/dashboard/dashboard.module.css
+193
app/src/app/dashboard/dashboard.module.css
···
1
+
.container {
2
+
max-width: 800px;
3
+
margin: 0 auto;
4
+
padding: 2rem 1rem;
5
+
}
6
+
7
+
.header {
8
+
display: flex;
9
+
justify-content: space-between;
10
+
align-items: center;
11
+
margin-bottom: 2rem;
12
+
flex-wrap: wrap;
13
+
gap: 1rem;
14
+
}
15
+
16
+
.header h1 {
17
+
background: linear-gradient(45deg, var(--primary-color), var(--secondary-color));
18
+
-webkit-background-clip: text;
19
+
background-clip: text;
20
+
color: transparent;
21
+
margin: 0;
22
+
}
23
+
24
+
.userInfo {
25
+
display: flex;
26
+
align-items: center;
27
+
gap: 1rem;
28
+
}
29
+
30
+
.logoutButton {
31
+
background-color: transparent;
32
+
color: var(--primary-color);
33
+
border: 1px solid var(--primary-color);
34
+
padding: 0.3rem 0.8rem;
35
+
font-size: 0.9rem;
36
+
}
37
+
38
+
.logoutButton:hover {
39
+
background-color: rgba(91, 173, 240, 0.1);
40
+
}
41
+
42
+
.card {
43
+
background: white;
44
+
border-radius: 8px;
45
+
box-shadow: 0 2px 10px rgba(0, 0, 0, 0.1);
46
+
padding: 2rem;
47
+
}
48
+
49
+
.description {
50
+
color: #666;
51
+
margin: 1rem 0;
52
+
line-height: 1.5;
53
+
}
54
+
55
+
.code {
56
+
background: #f5f5f5;
57
+
padding: 0.2rem 0.4rem;
58
+
border-radius: 3px;
59
+
font-family: monospace;
60
+
}
61
+
62
+
.error {
63
+
background-color: rgba(255, 82, 82, 0.1);
64
+
color: var(--error-color);
65
+
padding: 1rem;
66
+
border-radius: 4px;
67
+
margin: 1rem 0;
68
+
}
69
+
70
+
.success {
71
+
background-color: rgba(76, 175, 80, 0.1);
72
+
color: #4caf50;
73
+
padding: 1rem;
74
+
border-radius: 4px;
75
+
margin: 1rem 0;
76
+
}
77
+
78
+
.form {
79
+
margin-top: 1.5rem;
80
+
}
81
+
82
+
.formGroup {
83
+
margin-bottom: 1.5rem;
84
+
}
85
+
86
+
.formGroup label {
87
+
display: block;
88
+
margin-bottom: 0.5rem;
89
+
font-weight: 500;
90
+
}
91
+
92
+
.input {
93
+
width: 100%;
94
+
padding: 0.8rem;
95
+
border: 1px solid #ddd;
96
+
border-radius: 4px;
97
+
font-size: 1rem;
98
+
}
99
+
100
+
.input:focus {
101
+
border-color: var(--primary-color);
102
+
outline: none;
103
+
box-shadow: 0 0 0 2px rgba(91, 173, 240, 0.2);
104
+
}
105
+
106
+
.charCount {
107
+
text-align: right;
108
+
color: #666;
109
+
font-size: 0.8rem;
110
+
margin-top: 0.3rem;
111
+
}
112
+
113
+
.emojiGrid {
114
+
display: grid;
115
+
grid-template-columns: repeat(8, 1fr);
116
+
gap: 0.5rem;
117
+
}
118
+
119
+
@media (max-width: 600px) {
120
+
.emojiGrid {
121
+
grid-template-columns: repeat(6, 1fr);
122
+
}
123
+
}
124
+
125
+
.emojiButton {
126
+
background: #f5f5f5;
127
+
border: 1px solid #ddd;
128
+
border-radius: 4px;
129
+
font-size: 1.5rem;
130
+
aspect-ratio: 1/1;
131
+
display: flex;
132
+
align-items: center;
133
+
justify-content: center;
134
+
cursor: pointer;
135
+
transition: all 0.2s;
136
+
}
137
+
138
+
.emojiButton:hover {
139
+
background: #eaeaea;
140
+
transform: scale(1.05);
141
+
}
142
+
143
+
.selectedEmoji {
144
+
background: rgba(91, 173, 240, 0.2);
145
+
border-color: var(--primary-color);
146
+
}
147
+
148
+
.preview {
149
+
background: #f9f9f9;
150
+
padding: 1rem;
151
+
border-radius: 4px;
152
+
margin-bottom: 1.5rem;
153
+
}
154
+
155
+
.previewTitle {
156
+
font-weight: 500;
157
+
margin-bottom: 0.5rem;
158
+
color: #666;
159
+
}
160
+
161
+
.previewContent {
162
+
display: flex;
163
+
align-items: center;
164
+
gap: 0.5rem;
165
+
}
166
+
167
+
.previewEmoji {
168
+
font-size: 1.5rem;
169
+
}
170
+
171
+
.submitButton {
172
+
background-color: var(--primary-color);
173
+
color: white;
174
+
border: none;
175
+
border-radius: 4px;
176
+
padding: 0.8rem 1.5rem;
177
+
font-size: 1.1rem;
178
+
font-weight: 500;
179
+
cursor: pointer;
180
+
transition: all 0.2s;
181
+
width: 100%;
182
+
}
183
+
184
+
.submitButton:hover:not(:disabled) {
185
+
background-color: var(--secondary-color);
186
+
transform: translateY(-2px);
187
+
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
188
+
}
189
+
190
+
.submitButton:disabled {
191
+
background-color: #cccccc;
192
+
cursor: not-allowed;
193
+
}
+172
app/src/app/dashboard/page.tsx
+172
app/src/app/dashboard/page.tsx
···
1
+
'use client';
2
+
3
+
import { useState, useEffect } from 'react';
4
+
import { useRouter } from 'next/navigation';
5
+
import { useAuth } from '@/lib/auth-context';
6
+
import { createFlushingStatus } from '@/lib/bluesky-api';
7
+
import styles from './dashboard.module.css';
8
+
9
+
// List of relevant emojis for flushing situations
10
+
const EMOJIS = [
11
+
'🚽', '💩', '🧻', '📱', '💧', '🚿', '🛁', '📚', '💭', '💦', '🔊', '🤫',
12
+
'⏱️', '⌛', '🧠', '💨', '🙈', '🙉', '😬', '😌', '😓', '😳', '😅', '🥴'
13
+
];
14
+
15
+
export default function DashboardPage() {
16
+
const router = useRouter();
17
+
const { isAuthenticated, accessToken, did, handle, serializedKeyPair, clearAuth } = useAuth();
18
+
19
+
const [text, setText] = useState('');
20
+
const [selectedEmoji, setSelectedEmoji] = useState(EMOJIS[0]);
21
+
const [isSubmitting, setIsSubmitting] = useState(false);
22
+
const [error, setError] = useState<string | null>(null);
23
+
const [success, setSuccess] = useState<string | null>(null);
24
+
25
+
useEffect(() => {
26
+
// Redirect to home if not authenticated
27
+
if (!isAuthenticated) {
28
+
router.push('/');
29
+
}
30
+
}, [isAuthenticated, router]);
31
+
32
+
// Logout handler
33
+
const handleLogout = () => {
34
+
clearAuth();
35
+
router.push('/');
36
+
};
37
+
38
+
// Submit flushing status
39
+
const handleSubmit = async (e: React.FormEvent) => {
40
+
e.preventDefault();
41
+
42
+
if (!text) {
43
+
setError('Please enter a status message');
44
+
return;
45
+
}
46
+
47
+
if (!accessToken || !did || !serializedKeyPair) {
48
+
setError('Authentication information missing');
49
+
return;
50
+
}
51
+
52
+
setIsSubmitting(true);
53
+
setError(null);
54
+
setSuccess(null);
55
+
56
+
try {
57
+
// Deserialize key pair
58
+
const keyPairData = JSON.parse(serializedKeyPair);
59
+
const publicKey = await window.crypto.subtle.importKey(
60
+
'jwk',
61
+
keyPairData.publicKey,
62
+
{ name: 'ECDSA', namedCurve: 'P-256' },
63
+
true,
64
+
['verify']
65
+
);
66
+
const privateKey = await window.crypto.subtle.importKey(
67
+
'jwk',
68
+
keyPairData.privateKey,
69
+
{ name: 'ECDSA', namedCurve: 'P-256' },
70
+
true,
71
+
['sign']
72
+
);
73
+
const keyPair = { publicKey, privateKey };
74
+
75
+
// Create flushing status
76
+
await createFlushingStatus(accessToken, keyPair, did, text, selectedEmoji);
77
+
78
+
// Reset form and show success message
79
+
setText('');
80
+
setSuccess('Your flushing status has been updated!');
81
+
} catch (err: any) {
82
+
console.error('Failed to update status:', err);
83
+
setError(`Failed to update status: ${err.message || 'Unknown error'}`);
84
+
} finally {
85
+
setIsSubmitting(false);
86
+
}
87
+
};
88
+
89
+
if (!isAuthenticated) {
90
+
return null; // Will redirect in useEffect
91
+
}
92
+
93
+
return (
94
+
<div className={styles.container}>
95
+
<header className={styles.header}>
96
+
<h1>I'm Flushing Dashboard</h1>
97
+
<div className={styles.userInfo}>
98
+
<span>Logged in as: @{handle}</span>
99
+
<button onClick={handleLogout} className={styles.logoutButton}>
100
+
Logout
101
+
</button>
102
+
</div>
103
+
</header>
104
+
105
+
<div className={styles.card}>
106
+
<h2>Update Your Flushing Status</h2>
107
+
<p className={styles.description}>
108
+
Share what's happening in the bathroom right now. Your status
109
+
will be saved to your Bluesky account with the custom schema:
110
+
<code className={styles.code}>im.flushing.right.now</code>
111
+
</p>
112
+
113
+
{error && <div className={styles.error}>{error}</div>}
114
+
{success && <div className={styles.success}>{success}</div>}
115
+
116
+
<form onSubmit={handleSubmit} className={styles.form}>
117
+
<div className={styles.formGroup}>
118
+
<label htmlFor="status">What's your status?</label>
119
+
<input
120
+
type="text"
121
+
id="status"
122
+
value={text}
123
+
onChange={(e) => setText(e.target.value)}
124
+
placeholder="What's happening in the bathroom..."
125
+
maxLength={280}
126
+
className={styles.input}
127
+
disabled={isSubmitting}
128
+
/>
129
+
<div className={styles.charCount}>
130
+
{text.length}/280
131
+
</div>
132
+
</div>
133
+
134
+
<div className={styles.formGroup}>
135
+
<label>Select an emoji</label>
136
+
<div className={styles.emojiGrid}>
137
+
{EMOJIS.map((emoji) => (
138
+
<button
139
+
key={emoji}
140
+
type="button"
141
+
className={`${styles.emojiButton} ${
142
+
emoji === selectedEmoji ? styles.selectedEmoji : ''
143
+
}`}
144
+
onClick={() => setSelectedEmoji(emoji)}
145
+
disabled={isSubmitting}
146
+
>
147
+
{emoji}
148
+
</button>
149
+
))}
150
+
</div>
151
+
</div>
152
+
153
+
<div className={styles.preview}>
154
+
<div className={styles.previewTitle}>Preview:</div>
155
+
<div className={styles.previewContent}>
156
+
<span className={styles.previewEmoji}>{selectedEmoji}</span>
157
+
<span>{text || 'Your status will appear here'}</span>
158
+
</div>
159
+
</div>
160
+
161
+
<button
162
+
type="submit"
163
+
className={styles.submitButton}
164
+
disabled={isSubmitting || !text}
165
+
>
166
+
{isSubmitting ? 'Updating...' : 'Update Status'}
167
+
</button>
168
+
</form>
169
+
</div>
170
+
</div>
171
+
);
172
+
}
+96
app/src/app/globals.css
+96
app/src/app/globals.css
···
1
+
:root {
2
+
--primary-color: #5badf0;
3
+
--secondary-color: #6d4aff;
4
+
--background-color: #f9f9f9;
5
+
--text-color: #333;
6
+
--error-color: #ff5252;
7
+
}
8
+
9
+
* {
10
+
box-sizing: border-box;
11
+
margin: 0;
12
+
padding: 0;
13
+
}
14
+
15
+
html,
16
+
body {
17
+
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto, Oxygen,
18
+
Ubuntu, Cantarell, 'Fira Sans', 'Droid Sans', 'Helvetica Neue', sans-serif;
19
+
line-height: 1.6;
20
+
color: var(--text-color);
21
+
background-color: var(--background-color);
22
+
min-height: 100vh;
23
+
}
24
+
25
+
main {
26
+
max-width: 800px;
27
+
margin: 0 auto;
28
+
padding: 2rem;
29
+
}
30
+
31
+
a {
32
+
color: var(--primary-color);
33
+
text-decoration: none;
34
+
}
35
+
36
+
a:hover {
37
+
text-decoration: underline;
38
+
}
39
+
40
+
button {
41
+
cursor: pointer;
42
+
background-color: var(--primary-color);
43
+
color: white;
44
+
border: none;
45
+
border-radius: 4px;
46
+
padding: 0.5rem 1rem;
47
+
font-size: 1rem;
48
+
transition: background-color 0.2s;
49
+
}
50
+
51
+
button:hover {
52
+
background-color: var(--secondary-color);
53
+
}
54
+
55
+
.container {
56
+
display: flex;
57
+
flex-direction: column;
58
+
align-items: center;
59
+
justify-content: center;
60
+
min-height: 80vh;
61
+
}
62
+
63
+
.card {
64
+
background: white;
65
+
border-radius: 8px;
66
+
box-shadow: 0 2px 10px rgba(0, 0, 0, 0.1);
67
+
padding: 2rem;
68
+
margin: 1rem 0;
69
+
width: 100%;
70
+
}
71
+
72
+
.form-group {
73
+
margin-bottom: 1rem;
74
+
}
75
+
76
+
.form-group label {
77
+
display: block;
78
+
margin-bottom: 0.5rem;
79
+
font-weight: bold;
80
+
}
81
+
82
+
.form-group input,
83
+
.form-group textarea,
84
+
.form-group select {
85
+
width: 100%;
86
+
padding: 0.5rem;
87
+
border: 1px solid #ddd;
88
+
border-radius: 4px;
89
+
font-size: 1rem;
90
+
}
91
+
92
+
.error {
93
+
color: var(--error-color);
94
+
font-size: 0.9rem;
95
+
margin-top: 0.5rem;
96
+
}
+24
app/src/app/layout.tsx
+24
app/src/app/layout.tsx
···
1
+
import type { Metadata } from 'next';
2
+
import './globals.css';
3
+
import { AuthProvider } from '@/lib/auth-context';
4
+
5
+
export const metadata: Metadata = {
6
+
title: "I'm Flushing",
7
+
description: 'Share your flushing status with the Bluesky community',
8
+
};
9
+
10
+
export default function RootLayout({
11
+
children,
12
+
}: {
13
+
children: React.ReactNode;
14
+
}) {
15
+
return (
16
+
<html lang="en">
17
+
<body>
18
+
<AuthProvider>
19
+
<main>{children}</main>
20
+
</AuthProvider>
21
+
</body>
22
+
</html>
23
+
);
24
+
}
+50
app/src/app/page.module.css
+50
app/src/app/page.module.css
···
1
+
.container {
2
+
display: flex;
3
+
flex-direction: column;
4
+
align-items: center;
5
+
justify-content: center;
6
+
min-height: 80vh;
7
+
padding: 2rem;
8
+
}
9
+
10
+
.homeContainer {
11
+
text-align: center;
12
+
max-width: 600px;
13
+
}
14
+
15
+
.title {
16
+
font-size: 3rem;
17
+
margin-bottom: 1rem;
18
+
background: linear-gradient(45deg, var(--primary-color), var(--secondary-color));
19
+
-webkit-background-clip: text;
20
+
background-clip: text;
21
+
color: transparent;
22
+
}
23
+
24
+
.description {
25
+
font-size: 1.2rem;
26
+
color: #666;
27
+
margin-bottom: 2rem;
28
+
}
29
+
30
+
.btnContainer {
31
+
margin-top: 2rem;
32
+
}
33
+
34
+
.loginButton {
35
+
display: inline-block;
36
+
background-color: var(--primary-color);
37
+
color: white;
38
+
padding: 0.8rem 1.5rem;
39
+
border-radius: 4px;
40
+
font-size: 1.1rem;
41
+
font-weight: 500;
42
+
transition: all 0.2s ease;
43
+
}
44
+
45
+
.loginButton:hover {
46
+
background-color: var(--secondary-color);
47
+
transform: translateY(-2px);
48
+
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
49
+
text-decoration: none;
50
+
}
+21
app/src/app/page.tsx
+21
app/src/app/page.tsx
···
1
+
import Link from 'next/link';
2
+
import styles from './page.module.css';
3
+
4
+
export default function Home() {
5
+
// The OAuth flow starts on the client side, so we'll handle it there
6
+
return (
7
+
<div className={styles.container}>
8
+
<div className={styles.homeContainer}>
9
+
<h1 className={styles.title}>I'm Flushing</h1>
10
+
<p className={styles.description}>
11
+
Share your flushing status with the Bluesky community
12
+
</p>
13
+
<div className={styles.btnContainer}>
14
+
<Link href="/auth/login" className={styles.loginButton}>
15
+
Login with Bluesky
16
+
</Link>
17
+
</div>
18
+
</div>
19
+
</div>
20
+
);
21
+
}
+138
app/src/lib/auth-context.tsx
+138
app/src/lib/auth-context.tsx
···
1
+
'use client';
2
+
3
+
import { createContext, useContext, useState, useEffect, ReactNode } from 'react';
4
+
5
+
interface AuthContextType {
6
+
isAuthenticated: boolean;
7
+
accessToken: string | null;
8
+
refreshToken: string | null;
9
+
did: string | null;
10
+
handle: string | null;
11
+
serializedKeyPair: string | null;
12
+
dpopNonce: string | null;
13
+
setAuth: (auth: {
14
+
accessToken: string;
15
+
refreshToken: string;
16
+
did: string;
17
+
handle: string;
18
+
serializedKeyPair: string;
19
+
dpopNonce?: string | null;
20
+
}) => void;
21
+
clearAuth: () => void;
22
+
}
23
+
24
+
const AuthContext = createContext<AuthContextType | undefined>(undefined);
25
+
26
+
interface AuthProviderProps {
27
+
children: ReactNode;
28
+
}
29
+
30
+
export function AuthProvider({ children }: AuthProviderProps) {
31
+
const [isAuthenticated, setIsAuthenticated] = useState<boolean>(false);
32
+
const [accessToken, setAccessToken] = useState<string | null>(null);
33
+
const [refreshToken, setRefreshToken] = useState<string | null>(null);
34
+
const [did, setDid] = useState<string | null>(null);
35
+
const [handle, setHandle] = useState<string | null>(null);
36
+
const [serializedKeyPair, setSerializedKeyPair] = useState<string | null>(null);
37
+
const [dpopNonce, setDpopNonce] = useState<string | null>(null);
38
+
39
+
useEffect(() => {
40
+
// Load auth data from localStorage on initial mount
41
+
const storedAccessToken = localStorage.getItem('accessToken');
42
+
const storedRefreshToken = localStorage.getItem('refreshToken');
43
+
const storedDid = localStorage.getItem('did');
44
+
const storedHandle = localStorage.getItem('handle');
45
+
const storedKeyPair = localStorage.getItem('keyPair');
46
+
const storedDpopNonce = localStorage.getItem('dpopNonce');
47
+
48
+
if (storedAccessToken && storedDid && storedKeyPair) {
49
+
setAccessToken(storedAccessToken);
50
+
setRefreshToken(storedRefreshToken);
51
+
setDid(storedDid);
52
+
setHandle(storedHandle);
53
+
setSerializedKeyPair(storedKeyPair);
54
+
setDpopNonce(storedDpopNonce);
55
+
setIsAuthenticated(true);
56
+
}
57
+
}, []);
58
+
59
+
const setAuth = ({
60
+
accessToken,
61
+
refreshToken,
62
+
did,
63
+
handle,
64
+
serializedKeyPair,
65
+
dpopNonce = null
66
+
}: {
67
+
accessToken: string;
68
+
refreshToken: string;
69
+
did: string;
70
+
handle: string;
71
+
serializedKeyPair: string;
72
+
dpopNonce?: string | null;
73
+
}) => {
74
+
// Store auth data in state
75
+
setAccessToken(accessToken);
76
+
setRefreshToken(refreshToken);
77
+
setDid(did);
78
+
setHandle(handle);
79
+
setSerializedKeyPair(serializedKeyPair);
80
+
setDpopNonce(dpopNonce);
81
+
setIsAuthenticated(true);
82
+
83
+
// Store auth data in localStorage
84
+
localStorage.setItem('accessToken', accessToken);
85
+
localStorage.setItem('refreshToken', refreshToken);
86
+
localStorage.setItem('did', did);
87
+
localStorage.setItem('handle', handle);
88
+
localStorage.setItem('keyPair', serializedKeyPair);
89
+
if (dpopNonce) {
90
+
localStorage.setItem('dpopNonce', dpopNonce);
91
+
}
92
+
};
93
+
94
+
const clearAuth = () => {
95
+
// Clear auth data from state
96
+
setAccessToken(null);
97
+
setRefreshToken(null);
98
+
setDid(null);
99
+
setHandle(null);
100
+
setSerializedKeyPair(null);
101
+
setDpopNonce(null);
102
+
setIsAuthenticated(false);
103
+
104
+
// Clear auth data from localStorage
105
+
localStorage.removeItem('accessToken');
106
+
localStorage.removeItem('refreshToken');
107
+
localStorage.removeItem('did');
108
+
localStorage.removeItem('handle');
109
+
localStorage.removeItem('keyPair');
110
+
localStorage.removeItem('dpopNonce');
111
+
};
112
+
113
+
return (
114
+
<AuthContext.Provider
115
+
value={{
116
+
isAuthenticated,
117
+
accessToken,
118
+
refreshToken,
119
+
did,
120
+
handle,
121
+
serializedKeyPair,
122
+
dpopNonce,
123
+
setAuth,
124
+
clearAuth
125
+
}}
126
+
>
127
+
{children}
128
+
</AuthContext.Provider>
129
+
);
130
+
}
131
+
132
+
export function useAuth() {
133
+
const context = useContext(AuthContext);
134
+
if (context === undefined) {
135
+
throw new Error('useAuth must be used within an AuthProvider');
136
+
}
137
+
return context;
138
+
}
+108
app/src/lib/bluesky-api.ts
+108
app/src/lib/bluesky-api.ts
···
1
+
import { exportJWK, generateDPoPToken } from './bluesky-auth';
2
+
3
+
// Bluesky API utilities
4
+
const API_URL = 'https://bsky.social/xrpc';
5
+
6
+
// Create a custom lexicon schema for "im.flushing.right.now"
7
+
// This would normally be registered with the AT Protocol
8
+
export const FLUSHING_STATUS_NSID = 'im.flushing.right.now';
9
+
10
+
export interface FlushingRecord {
11
+
$type: typeof FLUSHING_STATUS_NSID;
12
+
text: string;
13
+
emoji: string;
14
+
createdAt: string;
15
+
}
16
+
17
+
// Make an authenticated request to the Bluesky API
18
+
export async function makeAuthenticatedRequest(
19
+
endpoint: string,
20
+
method: string,
21
+
accessToken: string,
22
+
keyPair: CryptoKeyPair,
23
+
dpopNonce: string | null = null,
24
+
body?: any
25
+
): Promise<any> {
26
+
const url = `${API_URL}/${endpoint}`;
27
+
const publicKey = await exportJWK(keyPair.publicKey);
28
+
29
+
const dpopToken = await generateDPoPToken(
30
+
keyPair.privateKey,
31
+
publicKey,
32
+
method,
33
+
url,
34
+
dpopNonce || undefined
35
+
);
36
+
37
+
const headers: HeadersInit = {
38
+
'Authorization': `DPoP ${accessToken}`,
39
+
'DPoP': dpopToken,
40
+
'Content-Type': 'application/json'
41
+
};
42
+
43
+
const requestOptions: RequestInit = {
44
+
method,
45
+
headers
46
+
};
47
+
48
+
if (body) {
49
+
requestOptions.body = JSON.stringify(body);
50
+
}
51
+
52
+
const response = await fetch(url, requestOptions);
53
+
54
+
// Handle DPoP nonce errors
55
+
if (response.status === 401) {
56
+
const newDpopNonce = response.headers.get('DPoP-Nonce');
57
+
if (newDpopNonce) {
58
+
return makeAuthenticatedRequest(endpoint, method, accessToken, keyPair, newDpopNonce, body);
59
+
}
60
+
}
61
+
62
+
if (!response.ok) {
63
+
const errorText = await response.text();
64
+
throw new Error(`API request failed: ${response.status} ${response.statusText}, ${errorText}`);
65
+
}
66
+
67
+
// If response is empty or not JSON, return null
68
+
const contentType = response.headers.get('content-type');
69
+
if (!contentType || !contentType.includes('application/json')) {
70
+
return null;
71
+
}
72
+
73
+
return await response.json();
74
+
}
75
+
76
+
// Get the user profile
77
+
export async function getProfile(
78
+
accessToken: string,
79
+
keyPair: CryptoKeyPair,
80
+
dpopNonce: string | null = null
81
+
): Promise<any> {
82
+
return makeAuthenticatedRequest('com.atproto.identity.resolveHandle', 'GET', accessToken, keyPair, dpopNonce);
83
+
}
84
+
85
+
// Create a flushing status record
86
+
export async function createFlushingStatus(
87
+
accessToken: string,
88
+
keyPair: CryptoKeyPair,
89
+
did: string,
90
+
text: string,
91
+
emoji: string,
92
+
dpopNonce: string | null = null
93
+
): Promise<any> {
94
+
const record: FlushingRecord = {
95
+
$type: FLUSHING_STATUS_NSID,
96
+
text,
97
+
emoji,
98
+
createdAt: new Date().toISOString()
99
+
};
100
+
101
+
const body = {
102
+
repo: did,
103
+
collection: FLUSHING_STATUS_NSID,
104
+
record
105
+
};
106
+
107
+
return makeAuthenticatedRequest('com.atproto.repo.createRecord', 'POST', accessToken, keyPair, dpopNonce, body);
108
+
}
+207
app/src/lib/bluesky-auth.ts
+207
app/src/lib/bluesky-auth.ts
···
1
+
// Bluesky OAuth client configuration
2
+
const BLUESKY_AUTH_SERVER = 'https://bsky.social';
3
+
const REDIRECT_URI = 'https://flushing.im/auth/callback';
4
+
const CLIENT_ID = 'https://flushing.im/client-metadata.json';
5
+
const SCOPES = 'atproto transition:generic';
6
+
7
+
// Generate a random string for PKCE and state
8
+
export function generateRandomString(length: number): string {
9
+
const characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789-._~';
10
+
let result = '';
11
+
const charactersLength = characters.length;
12
+
for (let i = 0; i < length; i++) {
13
+
result += characters.charAt(Math.floor(Math.random() * charactersLength));
14
+
}
15
+
return result;
16
+
}
17
+
18
+
// Generate the code challenge for PKCE
19
+
export async function generateCodeChallenge(codeVerifier: string): Promise<string> {
20
+
// Convert string to Uint8Array
21
+
const encoder = new TextEncoder();
22
+
const data = encoder.encode(codeVerifier);
23
+
24
+
// Hash the data using SHA-256
25
+
const hashBuffer = await crypto.subtle.digest('SHA-256', data);
26
+
27
+
// Convert hash buffer to base64url format
28
+
const hashArray = Array.from(new Uint8Array(hashBuffer));
29
+
const hashBase64 = btoa(String.fromCharCode.apply(null, hashArray));
30
+
31
+
// Convert base64 to base64url by replacing characters
32
+
return hashBase64
33
+
.replace(/\+/g, '-')
34
+
.replace(/\//g, '_')
35
+
.replace(/=+$/, '');
36
+
}
37
+
38
+
// Generate a DPoP JWK key pair
39
+
export async function generateDPoPKeyPair(): Promise<CryptoKeyPair> {
40
+
return await window.crypto.subtle.generateKey(
41
+
{
42
+
name: 'ECDSA',
43
+
namedCurve: 'P-256'
44
+
},
45
+
true, // extractable
46
+
['sign', 'verify']
47
+
);
48
+
}
49
+
50
+
// Export the key to JWK format
51
+
export async function exportJWK(key: CryptoKey): Promise<JsonWebKey> {
52
+
return await window.crypto.subtle.exportKey('jwk', key);
53
+
}
54
+
55
+
// Generate a DPoP token
56
+
export async function generateDPoPToken(
57
+
privateKey: CryptoKey,
58
+
publicKey: JsonWebKey,
59
+
method: string,
60
+
url: string,
61
+
nonce?: string
62
+
): Promise<string> {
63
+
const now = Math.floor(Date.now() / 1000);
64
+
const jti = generateRandomString(16);
65
+
66
+
const header = {
67
+
alg: 'ES256',
68
+
typ: 'dpop+jwt',
69
+
jwk: publicKey
70
+
};
71
+
72
+
const payload: any = {
73
+
jti,
74
+
htm: method,
75
+
htu: url,
76
+
iat: now
77
+
};
78
+
79
+
if (nonce) {
80
+
payload.nonce = nonce;
81
+
}
82
+
83
+
const encodedHeader = btoa(JSON.stringify(header))
84
+
.replace(/\+/g, '-')
85
+
.replace(/\//g, '_')
86
+
.replace(/=+$/, '');
87
+
88
+
const encodedPayload = btoa(JSON.stringify(payload))
89
+
.replace(/\+/g, '-')
90
+
.replace(/\//g, '_')
91
+
.replace(/=+$/, '');
92
+
93
+
const toSign = `${encodedHeader}.${encodedPayload}`;
94
+
const encoder = new TextEncoder();
95
+
const data = encoder.encode(toSign);
96
+
97
+
const signature = await window.crypto.subtle.sign(
98
+
{
99
+
name: 'ECDSA',
100
+
hash: { name: 'SHA-256' },
101
+
},
102
+
privateKey,
103
+
data
104
+
);
105
+
106
+
const signatureArray = Array.from(new Uint8Array(signature));
107
+
const encodedSignature = btoa(String.fromCharCode.apply(null, signatureArray))
108
+
.replace(/\+/g, '-')
109
+
.replace(/\//g, '_')
110
+
.replace(/=+$/, '');
111
+
112
+
return `${encodedHeader}.${encodedPayload}.${encodedSignature}`;
113
+
}
114
+
115
+
// Get the authorization URL for Bluesky OAuth
116
+
export async function getAuthorizationUrl(): Promise<{ url: string, state: string, codeVerifier: string, keyPair: CryptoKeyPair }> {
117
+
const state = generateRandomString(32);
118
+
const codeVerifier = generateRandomString(64);
119
+
const codeChallenge = await generateCodeChallenge(codeVerifier);
120
+
const keyPair = await generateDPoPKeyPair();
121
+
const publicKey = await exportJWK(keyPair.publicKey);
122
+
123
+
// Initial PAR request to get DPoP nonce
124
+
const parEndpoint = `${BLUESKY_AUTH_SERVER}/.well-known/oauth-authorization-server`;
125
+
const parResponse = await fetch(parEndpoint, {
126
+
method: 'GET',
127
+
headers: {
128
+
'Content-Type': 'application/json',
129
+
},
130
+
});
131
+
132
+
if (!parResponse.ok) {
133
+
throw new Error(`Failed to fetch OAuth metadata: ${parResponse.statusText}`);
134
+
}
135
+
136
+
const metadata = await parResponse.json();
137
+
const parsEndpoint = metadata.pushed_authorization_request_endpoint;
138
+
139
+
// Now we need to make a PAR request
140
+
// Note: In a real implementation, you would need to handle the DPoP nonce exchange
141
+
// For simplicity, we're going directly to the authorization endpoint
142
+
143
+
const authUrl = `${BLUESKY_AUTH_SERVER}/oauth/authorize` +
144
+
`?client_id=${encodeURIComponent(CLIENT_ID)}` +
145
+
`&response_type=code` +
146
+
`&redirect_uri=${encodeURIComponent(REDIRECT_URI)}` +
147
+
`&scope=${encodeURIComponent(SCOPES)}` +
148
+
`&state=${encodeURIComponent(state)}` +
149
+
`&code_challenge=${encodeURIComponent(codeChallenge)}` +
150
+
`&code_challenge_method=S256`;
151
+
152
+
return {
153
+
url: authUrl,
154
+
state,
155
+
codeVerifier,
156
+
keyPair
157
+
};
158
+
}
159
+
160
+
// Get access token from authorization code
161
+
export async function getAccessToken(
162
+
code: string,
163
+
codeVerifier: string,
164
+
keyPair: CryptoKeyPair,
165
+
dpopNonce?: string
166
+
): Promise<any> {
167
+
const tokenEndpoint = `${BLUESKY_AUTH_SERVER}/oauth/token`;
168
+
169
+
const publicKey = await exportJWK(keyPair.publicKey);
170
+
const dpopToken = await generateDPoPToken(
171
+
keyPair.privateKey,
172
+
publicKey,
173
+
'POST',
174
+
tokenEndpoint,
175
+
dpopNonce
176
+
);
177
+
178
+
const response = await fetch(tokenEndpoint, {
179
+
method: 'POST',
180
+
headers: {
181
+
'Content-Type': 'application/x-www-form-urlencoded',
182
+
'DPoP': dpopToken
183
+
},
184
+
body: new URLSearchParams({
185
+
grant_type: 'authorization_code',
186
+
code,
187
+
redirect_uri: REDIRECT_URI,
188
+
client_id: CLIENT_ID,
189
+
code_verifier: codeVerifier
190
+
})
191
+
});
192
+
193
+
if (response.status === 401) {
194
+
// Handle DPoP nonce errors
195
+
const dpopNonce = response.headers.get('DPoP-Nonce');
196
+
if (dpopNonce) {
197
+
return getAccessToken(code, codeVerifier, keyPair, dpopNonce);
198
+
}
199
+
}
200
+
201
+
if (!response.ok) {
202
+
const errorText = await response.text();
203
+
throw new Error(`Token request failed: ${response.status} ${response.statusText}, ${errorText}`);
204
+
}
205
+
206
+
return await response.json();
207
+
}
+27
app/tsconfig.json
+27
app/tsconfig.json
···
1
+
{
2
+
"compilerOptions": {
3
+
"target": "es5",
4
+
"lib": ["dom", "dom.iterable", "esnext"],
5
+
"allowJs": true,
6
+
"skipLibCheck": true,
7
+
"strict": true,
8
+
"noEmit": true,
9
+
"esModuleInterop": true,
10
+
"module": "esnext",
11
+
"moduleResolution": "bundler",
12
+
"resolveJsonModule": true,
13
+
"isolatedModules": true,
14
+
"jsx": "preserve",
15
+
"incremental": true,
16
+
"plugins": [
17
+
{
18
+
"name": "next"
19
+
}
20
+
],
21
+
"paths": {
22
+
"@/*": ["./src/*"]
23
+
}
24
+
},
25
+
"include": ["next-env.d.ts", "**/*.ts", "**/*.tsx", ".next/types/**/*.ts"],
26
+
"exclude": ["node_modules"]
27
+
}
+54
contextual info for claude/API Hosts and Auth Bluesky.md
+54
contextual info for claude/API Hosts and Auth Bluesky.md
···
1
+
---
2
+
title: "API Hosts and Auth | Bluesky"
3
+
source: "https://docs.bsky.app/docs/advanced-guides/api-directory"
4
+
author:
5
+
published:
6
+
created: 2025-03-07
7
+
description: "Lexicon API definitions do not always indicate which network services implement the endpoint, and whether auth is required when making HTTP requests. This guide describes the most common API request patterns, and lists the specific hostnames for Bluesky-operated services."
8
+
tags:
9
+
- "clippings"
10
+
---
11
+
Lexicon API definitions do not always indicate which network services implement the endpoint, and whether auth is required when making HTTP requests. This guide describes the most common API request patterns, and lists the specific hostnames for Bluesky-operated services.
12
+
13
+
As a reminder, the Bluesky application is built on atproto, a decentralized social web protocol. Unlike some social media platforms, there is not one centralized API. More like the classic web, there can be multiple independent service providers and account hosts.
14
+
15
+
## Common Request Types
16
+
17
+
Most client API requests fall in one of a few categories.
18
+
19
+
**Data record writes, and account management:** all public data in the network exists as records in user repositories on their PDS instance, which means all data creation, update, and deletion, for all applications, involves repository API calls to the PDS. This includes things like creating posts, updating profiles, following and unfollowing, etc. These actions require authentication, are made to the user's PDS instance (which needs to be resolved or discovered as part of creating an auth session), and usually involve the `com.atproto.*` Lexicons. Account management requests, such as updating the account handle, also go directly to the PDS. See [PDS Entryway](https://docs.bsky.app/docs/advanced-guides/entryway) for the distinction between PDS instances and the "entryway" service.
20
+
21
+
**Authenticated Bluesky app requests:** API requests relevant to the Bluesky Social app (`app.bsky.*` Lexicon endpoints) are routed to a Bluesky AppView. This includes reads, as well as private data writes which don't involve repository records, such as "mutes". In the current atproto architecture, these requests all go through the user PDS instance, and get proxied to the correct service. For most services, the proxying is controlled by the `atproto-proxy` header, but as of Fall 2024 this is still configured server-side for the Bluesky AppView, and the `atproto-proxy` is not required.
22
+
23
+
**Public Bluesky app requests:** many Bluesky Lexicon endpoints are public, and do not require authentication. These endpoints can be made directly against the Bluesky AppView, preferably via the `https://public.api.bsky.app` hostname, which includes additional caching.
24
+
25
+
Note that it is perfectly fine for authenticated clients to use authenticated requests to hit public Bluesky API endpoints. It is often simpler for authenticated clients to make all requests via the PDS and proxying, instead of juggling multiple API client connections.
26
+
27
+
**Firehose:** data updates from the entire network can be streamed over a WebSocket using the `com.atproto.sync.subscribeRepos` Lexicon endpoint. This endpoint does not require auth, and can be made to individual PDS instances (for data just from that PDS), or to a Relay to receive updates from the entire network.
28
+
29
+
**Other Proxied App Requests:** for example, the `chat.bsky.*` centralized chat/DM APIs, or the `tools.ozone.*` moderation APIs. These are generally authenticated, routed via the PDS, and use service proxying to route to the relevant service instance.
30
+
31
+
## Other Request Types
32
+
33
+
There are a few other patterns of API requests.
34
+
35
+
**Fetching Content from Original PDS:** sometimes a service or tool needs to request blobs, account status, or repository directly from the original PDS. These are usually un-authenticated requests, and use `com.atproto.*` Lexicons. The specific PDS hostname needs to be resolved from the relevant account's identity (DID document).
36
+
37
+
**Inter-Service Requests:** most clients can rely on PDS instances to handle service request proxying, but PDS implementations themselves need to handle those requests. Service DIDs need to be resolved to specific HTTPS hostnames, and service auth tokens generated and signed. Receiving services need to decode and verify the auth token.
38
+
39
+
**Admin Auth:** used for a few specific operational tasks, like administering PDS instances, or bulk operations against Ozone moderation services. Requests are made directly to the relevant service, using fixed/static Bearer tokens.
40
+
41
+
**Bulk Data Requests:** for example, when backfilling existing data from the network in to a new service instance, like an AppView instance. It is possible to distribute load across all the PDS instances, or centralize requests to a Relay instance, which may have a faster network connection.
42
+
43
+
## Bluesky Services
44
+
45
+
This table summarizes the hostnames for Bluesky-operated atproto network services.
46
+
47
+
| Type | Host URL | Service DID |
48
+
| --- | --- | --- |
49
+
| Relay | `https://bsky.network` | n/a |
50
+
| Entryway | `https://bsky.social` | n/a |
51
+
| PDS Instances | `https://<NAME>.<REGION>.host.bsky.network` | n/a |
52
+
| bsky AppView | `https://api.bsky.app` | `did:web:api.bsky.app#bsky_appview` |
53
+
| Chat / DMs | `https://api.bsky.chat` | `did:web:api.bsky.chat#bsky_chat` |
54
+
| Ozone / Moderation | `https://mod.bsky.app` | `did:plc:ar7c4by46qjdydhdevvrndac#atproto_labeler` |
+54
contextual info for claude/Custom Schemas Bluesky.md
+54
contextual info for claude/Custom Schemas Bluesky.md
···
1
+
---
2
+
title: "Custom Schemas | Bluesky"
3
+
source: "https://docs.bsky.app/docs/advanced-guides/custom-schemas"
4
+
author:
5
+
published:
6
+
created: 2025-03-07
7
+
description: "The AT Protocol, and specifically Lexicon, provides a toolkit for creating decentralization social applications. Lexicon is meant to be a social coordination tool. It's an explicit way to announce the schema that some data adheres to and compare it against the schemas that your application understands."
8
+
tags:
9
+
- "clippings"
10
+
---
11
+
The AT Protocol, and specifically Lexicon, provides a toolkit for creating decentralization social applications. Lexicon is meant to be a social coordination tool. It's an explicit way to announce the schema that some data adheres to and compare it against the schemas that your application understands.
12
+
13
+
The Bluesky microblogging application uses schemas defined in the `app.bsky.*` namespace. We're excited for other applications to emerge on atproto as well. Right now, we artificially prevent non-Bluesky records from being created by our PDSs. However, we'll be lifting that limitation soon.
14
+
15
+
When creating new lexicons, you *must* identity them under a domain name that you control.
16
+
17
+
Lexicons may be used to specify record types, API routes, or new sub-schemas for extension points in lexicons that you do not control.
18
+
19
+
To read a more in-depth description of Lexicon, check out the [atproto specs](https://atproto.com/guides/lexicon).
20
+
21
+
### Records
22
+
23
+
A new social mode will likely require a new set of record Lexicons. These schemas define the basic pieces of data that make of that social mode.
24
+
25
+
A lot of care should go into defining these record schemas, as they can be very difficult to change once records are published and referenced in the wild.
26
+
27
+
Records *may* be used across applications, though there is no requirement to do so. For instance, a long-form blogging application on atproto *may* use the profile records from Bluesky, but they are also free to define their own records.
28
+
29
+
### APIs
30
+
31
+
In the same manner in which Bluesky (the company) runs the Bluesky App View to provide views to its clients, a developer that is creating a new applciation will need to create and run an API service (or "App View") for their application.
32
+
33
+
Of course, they may use the already existing PDSs and Relays in the network in order to ingest all relevant user data. But to create views of the underlying records, they will need to index that data and provide views over it.
34
+
35
+
In order to facilitate open and swappable APIs, developers should create and publish lexicons that describe the API routes for their service.
36
+
37
+
### Sub-schemas
38
+
39
+
Within existing application spaces, there are extension points where developers have the ability to define new schemas. These can often be found by looking for "open unions" in the existing lexicons.
40
+
41
+
A good example in the `app.bsky` namespace is the post embed type. This is an open union in the post record that currently can contain
42
+
43
+
- images (`app.bsky.embed.images`)
44
+
- external link (`app.bsky.embed.external`)
45
+
- record - for instance a quote post (`app.bsky.embed.record`)
46
+
- record alongside some media like images (`app.bsky.embed.recordWithMedia`)
47
+
48
+
Developers can define additional schemas to go in this open union.
49
+
50
+
For instance, a developer that owns the site `bluesky-graphs.com` and wants to embed graphs in bluesky posts may create an embed type called `com.bluesky-graphs.graph`. That developer has full control over how the graph data is encoded.
51
+
52
+
Of course, after doing so, the Bluesky client will not have the logic to present the graph to the user, and will show an empty embed. Experimental clients, however, may implement logic for some of these experimental embeds. As they gain traction and social consensus, these embeds may make their way into more prominent clients.
53
+
54
+
We plan to add a generic fallback mechanism for clients that encounter embeds they are not familiar with, so that end users can get notified that they're missing context on some content.
+130
contextual info for claude/Event Stream - AT Protocol.md
+130
contextual info for claude/Event Stream - AT Protocol.md
···
1
+
---
2
+
title: "Event Stream - AT Protocol"
3
+
source: "https://atproto.com/specs/event-stream"
4
+
author:
5
+
- "[[AT Protocol]]"
6
+
published:
7
+
created: 2025-03-07
8
+
description: "Network wire protocol for subscribing to a stream of Lexicon objects"
9
+
tags:
10
+
- "clippings"
11
+
---
12
+
In addition to regular [HTTP API](https://atproto.com/specs/xrpc) endpoints, atproto supports continuous event streams. Message schemas and endpoint names are transport-agnostic and defined in [Lexicons](https://atproto.com/specs/lexicon). The initial encoding and transport scheme uses binary [DAG-CBOR](https://ipld.io/docs/codecs/known/dag-cbor/) encoding over [WebSockets](https://en.wikipedia.org/wiki/WebSocket).
13
+
14
+
The Lexicon type for streams is `subscription`. The schema includes an identifier (`id`) for the endpoint, a `message` schema (usually a union, allowing multiple message types), and a list of error types (`errors`).
15
+
16
+
Clients subscribe to a specific stream by initiating a connection at the indicated endpoint. Streams are currently one-way, with messages flowing from the server to the client. Clients may provide query parameters to configure the stream when opening the connection.
17
+
18
+
A **backfill window** mechanism allows clients to catch up with stream messages they may have missed. At a high level, this works by assigning monotonically increasing sequence numbers to stream events, and allowing clients to specify an initial sequence number when initiating a connection. The intent of this mechanism is to ensure reliable delivery of events following disruptions during a reasonable time window (eg, hours or days). It is not to enable clients to roll all the way back to the beginning of the stream.
19
+
20
+
All of the initial subscription Lexicons in the `com.atproto` namespace use the backfill mechanism. However, a backfill mechanism (and even cursors, which we define below) is not *required* for streams. Subscription endpoints which do not require reliable delivery do not need to implement a backfill mechanism or use sequence numbers.
21
+
22
+
The initial subscription endpoints are also public and do not require authentication or prior permission to subscribe (though resource limits may be imposed on client). But subscription endpoints may require authentication at connection time, using the existing HTTP API (XRPC) authentication methods.
23
+
24
+
To summarize, messages are encoded as DAG-CBOR and sent over a binary WebSocket. Clients connect to to a specific HTTP endpoint, with query parameters, then upgrade to WebSocket. Every WebSocket frame contains two DAG-CBOR objects, with bytes concatenated together: a header (indicating message type), and the actual message.
25
+
26
+
The WebSockets "living standard" is currently maintained by [WHATWG](https://en.wikipedia.org/wiki/WHATWG), and can be found in full at [https://websockets.spec.whatwg.org/](https://websockets.spec.whatwg.org/).
27
+
28
+
### Connection
29
+
30
+
Clients initialize stream subscriptions by opening an HTTP connection and upgrading to a WebSocket. HTTPS and "WebSocket Secure" (`wss://`) on the default port (443) should be used for all connections on the internet. HTTP, cleartext WebSocket (`ws://`), and non-standard ports should only be used for testing, development, and local connections (for example, behind a reverse proxy implementing SSL). From the client perspective, failure to upgrade connection to a WebSocket is an error.
31
+
32
+
Query parameters may be provided in the initial HTTP request to configure the stream in an application-specific way, as specified in the endpoint's Lexicon schema.
33
+
34
+
Errors are usually returned through the stream itself. Connection-time errors are sent as the first message on the stream, and then the server drops the connection. But some errors can not be handled through the stream, and are returned as HTTP errors:
35
+
36
+
- `405 Method Not Allowed`: Returned to client for non-GET HTTP requests to a stream endpoint.
37
+
- `426 Upgrade Required`: Returned to client if `Upgrade` header is not included in a request to a stream endpoint.
38
+
- `429 Too Many Requests`: Frequently used for rate-limiting. Client may try again after a delay. Support for the `Retry-After` header is encouraged.
39
+
- `500 Internal Server Error`: Client may try again after a delay
40
+
- `501 Not Implemented`: Service does not implement WebSockets or streams, at least for this endpoint. Client should not try again.
41
+
- `502 Bad Gateway`, `503 Service Unavailable`, `504 Gateway Timeout`: Client may try again after a delay
42
+
43
+
Servers *should* return HTTP bodies as JSON with the standard XRPC error message schema for these status codes. But clients also need to be robust to unexpected response body formats. A common situation is receiving a default load-balancer or reverse-proxy error page during scheduled or unplanned downtime.
44
+
45
+
Either the server or the client may decided to drop an open stream connection if there have been no messages for some time. It is also acceptable to leave connections open indefinitely.
46
+
47
+
### Framing
48
+
49
+
Each binary WebSocket frame contains two DAG-CBOR objects, concatenated. The first is a **header** and the second is the **payload.**
50
+
51
+
The header DAG-CBOR object has the following fields:
52
+
53
+
- `op` ("operation", integer, required): fixed values, indicating what this frame contains
54
+
- `1`: a regular message, with type indicated by `t`
55
+
- `-1`: an error message
56
+
- `t` ("type", string, optional): required if `op` is `1`, indicating the Lexicon sub-type for this message, in short form. Does not include the full Lexicon identifier, just a fragment. Eg: `#commit`. Should not be included in header if `op` is `-1`.
57
+
58
+
Clients should ignore frames with headers that have unknown `op` or `t` values. Unknown fields in both headers and payloads should be ignored. Invalid framing or invalid DAG-CBOR encoding are hard errors, and the client should drop the entire connection instead of skipping the frame. Servers should ignore any frames received from the client, not treat them as errors.
59
+
60
+
Error payloads all have the following fields:
61
+
62
+
- `error` (string, required): the error type name, with no namespace or `#` prefix
63
+
- `message` (string, optional): a description of the error
64
+
65
+
Streams should be closed immediately following transmitting or receiving an error frame.
66
+
67
+
Message payloads must always be objects. They should omit the `$type` field, as this information is already indicated in the header. There is no specific limit on the size of WebSocket frames in atproto, but they should be kept reasonably small (around a couple megabytes).
68
+
69
+
If a client can not keep up with the rate of messages, the server may send a "too slow" error and close the connection.
70
+
71
+
### Sequence Numbers
72
+
73
+
Streams can optionally make use of per-message sequence numbers to improve the reliability of transmission. Clients keep track of the last sequence number they received and successfully processed, and can specify that number after a re-connection to receive any missed messages, up to some roll-back window. Servers persist no client state across connections. The semantics are similar to [Apache Kafka](https://en.wikipedia.org/wiki/Apache_Kafka)'s consumer groups and other stream-processing protocols.
74
+
75
+
Subscription Lexicons must include a `seq` field (integer type), and a `cursor` query parameter (integer type). Not all message types need to include `seq`. Errors do not, and it is common to have an `#info` message type that is not persisted.
76
+
77
+
Sequence numbers are always positive integers (non-zero), and increase monotonically, but otherwise have flexible semantics. They may contain arbitrary gaps. For example, they might be timestamps.
78
+
79
+
To prevent confusion when working with Javascript (which by default represents all numbers as floating point), sequence numbers should be limited to the range of integers which can safely be represented by a 64-bit float. That is, the integer range `1` to `2^53` (not inclusive on the upper bound).
80
+
81
+
The connection-time rules for cursors and sequence numbers:
82
+
83
+
- no `cursor` is specified: the server starts transmitting from the current stream position
84
+
- `cursor` is higher than current `seq` ("in the future"): server sends an error message and closes connection
85
+
- `cursor` is in roll-back window: server sends any persisted messages with greater-or-equal `seq` number, then continues once "caught up" with current stream
86
+
- `cursor` is older than roll-back window: the first message in stream is an info indicating that `cursor` is too-old, then starts at the oldest available `seq` and sends the entire roll-back window, then continues with current stream
87
+
- `cursor` is `0`: server will start at the oldest available `seq`, send the entire roll-back window, then continue with current stream
88
+
89
+
The scope for sequence numbers is the combination of service provider (hostname) and endpoint (NSID). This roughly corresponds to the `wss://` URL used for connections. That is, sequence numbers may or may not be unique across different stream endpoints on the same service.
90
+
91
+
Services should ensure that sequence numbers are not re-used, usually by committing events (with sequence number) to robust persistent storage before transmitting them over streams.
92
+
93
+
In some catastrophic failure modes (or large changes to infrastructure), it is possible that a server would lose data from the backfill window, and need to reset the sequence number back to `1`. In this case, if a client re-connects with a higher number, the server would send back a `FutureCursor` error to the client. The client needs to decide what strategy to follow in these scenarios. We suggest that clients treat out-of-order or duplicate sequence numbers as an error, not process the message, and drop the connection. Most clients should not reset sequence state without human operator intervention, though this may be a reasonable behavior for some ephemeral clients not requiring reliable delivery of every event in the stream.
94
+
95
+
The current stream transport is primarily designed for server-to-server data synchronization. It is also possible for web applications to connect directly from end-user browsers, but note that decoding binary frames and DAG-CBOR is non-trivial.
96
+
97
+
The combination of HTTP redirects and WebSocket upgrades is not consistently supported by WebSocket client libraries. Support is not specifically required or forbidden in atproto.
98
+
99
+
Supported versions of the WebSockets standard are not specified by atproto. The current stable WebSocket standard is version 13. Implementations should make reasonable efforts to support modern versions, with some window of backwards compatibility.
100
+
101
+
WebSockets have distinct resource rate-limiting and denial-of-service issues. Network bandwidth limits and throttling are recommended for both servers and clients. Servers should tune concurrent connection limits and buffer sizes to prevent resource exhaustion.
102
+
103
+
If services need to reset sequence state, it is recommended to chose a new initial sequence number with a healthy margin above any previous sequence number. For example, after persistent storage loss, or if clearing prior stream state.
104
+
105
+
URLs referencing a stream endpoint at a particular host should generally use `wss://` as the URI scheme (as opposed to `https://`).
106
+
107
+
As mentioned in the "Connection" section, only `wss://` (SSL) should be used for stream connections over the internet. Public services should reject non-SSL connections.
108
+
109
+
Most HTTP XRPC endpoints work with content in JSON form, while stream endpoints work directly with DAG-CBOR objects as untrusted input. Precautions must be taken against hostile data encoding and data structure manipulation. Specific issues are discussed in the [Data Model](https://atproto.com/specs/data-model) and [Repository](https://atproto.com/specs/repository) specifications.
110
+
111
+
Event Streams are one of the newest components of the AT Protocol, and the details are more likely to be iterated on compared to other components.
112
+
113
+
The sequence number scheme may be tweaked to better support sharded streams. The motivation would be handle higher data throughputs over the public internet by splitting across multiple connections.
114
+
115
+
Additional transports (other than WebSocket) and encodings (other than DAG-CBOR) may be specified. For example, JSON payloads in text WebSocket frames would be simpler to decode in browsers.
116
+
117
+
Additional WebSocket features may be adopted:
118
+
119
+
- transport compression "extensions" like `permessage-deflate`
120
+
- definition of a sub-protocol
121
+
- bi-directional messaging
122
+
- 1000-class response codes
123
+
124
+
Ambiguities in this specification may be resolved, or left open. For example:
125
+
126
+
- HTTP redirects
127
+
- CORS and other issues for browser connections
128
+
- maximum message/frame size
129
+
130
+
Authentication schemes may be supported, similar to those for regular HTTP XRPC endpoints.
+49
contextual info for claude/Federation Architecture Bluesky.md
+49
contextual info for claude/Federation Architecture Bluesky.md
···
1
+
---
2
+
title: "Federation Architecture | Bluesky"
3
+
source: "https://docs.bsky.app/docs/advanced-guides/federation-architecture"
4
+
author:
5
+
published:
6
+
created: 2025-03-07
7
+
description: "The AT Protocol is made up of a bunch of pieces that stack together. Federation means that anyone can run the parts that make up the AT Protocol themselves, such as their own server."
8
+
tags:
9
+
- "clippings"
10
+
---
11
+
The AT Protocol is made up of a bunch of pieces that stack together. Federation means that anyone can run the parts that make up the AT Protocol themselves, such as their own server.
12
+
13
+
The three main services are personal data servers (PDS), Relays, and App Views. Developers can also run feed generators (custom feeds), and labelers are in active development.
14
+
15
+
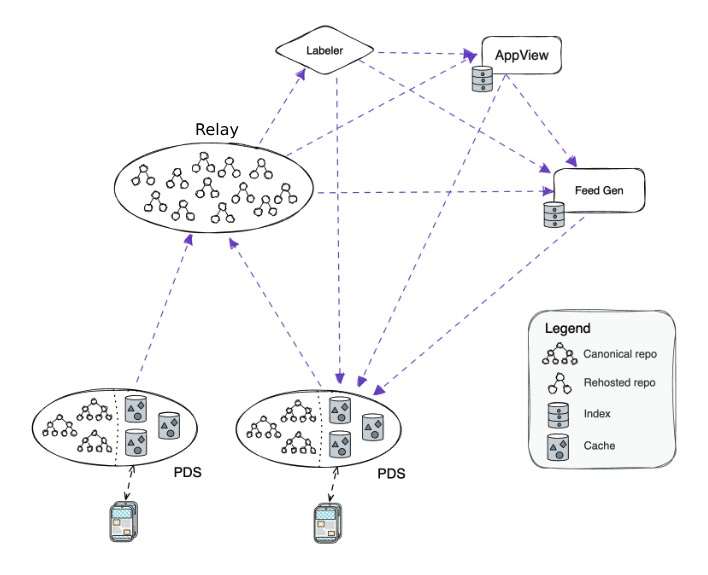
16
+
17
+
## Personal Data Server (PDS)
18
+
19
+
A PDS acts as the participant’s agent in the network. This is what hosts your data (like the posts you’ve created) in your repository. It also handles your account & login, manages your repo’s signing key, stores any of your private data (like which accounts you have muted), and handles the services you talk to for any request.
20
+
21
+
## Relay
22
+
23
+
The Relay handles "big-world" networking. It crawls the network, gathering as much data as it can, and outputs it in one big stream for other services to use. It’s analogous to a firehose provider or a super-powered relay node.
24
+
25
+
Anyone can host a Relay, though it’s a fairly resource-demanding service. In all likelihood, there may be a few large full-network providers, and then a long tail of partial-network providers. Small bespoke Relays could also service tightly or well-defined slices of the network, like a specific new application or a small community.
26
+
27
+
## App Views
28
+
29
+
An App View is the piece that actually assembles your feed and all the other data you see in the app, and is generally expected to be downstream from a Relay's firehose of data. This is a highly semantically-aware service that produces aggregations across the network and views over some subset of the network. This is analogous to a prism that takes in the Relay's raw firehose of data from the network, and outputs views that enable an app to show a curated feed to a user. For example, the Relay might crawl to grab data such as a certain post’s likes and reposts, and the app view will output the count of those metrics.
30
+
31
+
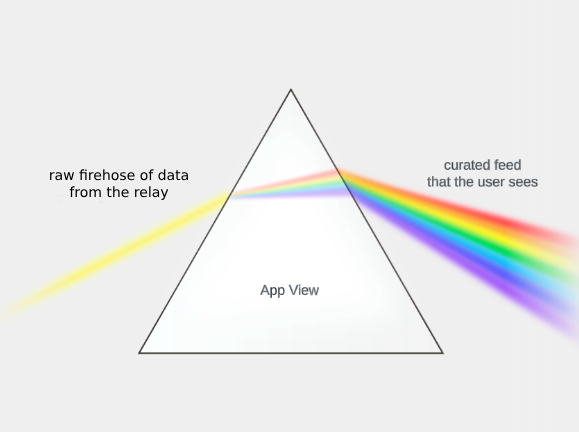
32
+
33
+
There will also be an ecosystem of App Views for each lexicon, or “social mode,” deployed on the network. For example, Bluesky currently supports a micro-blogging mode: the `app.bsky` lexicon. Developers who create new lexicons would likely deploy a corresponding App View that understands their lexicon to service their users. Other lexicons could include video or long-form blogging, or different ways of organizing like groups and forums. By bootstrapping off of an existing Relay, data collation will already be taken care of for these new applications. They need only provide the indexing behaviors necessary for their application.
34
+
35
+
## “Big World” Design
36
+
37
+
The AT Protocol is architected in a “big world with small world fallbacks” way, modeled after the open web itself. With the web, individual computers upload content to the network, and then all of that content is then broadcasted back to other computers. Similarly, with the AT Protocol, we’re sending messages to a much smaller number of big aggregators, which then broadcast that data to personal data servers across the network. Additionally, we solve the major problems that have surfaced from the web through self-certifying data, open schematic data and APIs, and account portability.
38
+
39
+
On a technical level, prioritizing big-world indexing over small world networking has multiple benefits.
40
+
41
+
- It significantly reduces the load on PDSs, making it easier to self-host — you could easily run your own server.
42
+
- It improves discoverability of content outside of your immediate neighbors — people want to use social media to see content from outside of their network.
43
+
- It improves the quality of experience for everyone in the network — fewer dropped messages or out-of-sync metrics.
44
+
45
+
Given all that, our proposed methodology here of networking through Relays instead of server-to-server isn’t prescriptive. The protocol is actually explicitly designed to work both ways.
46
+
47
+
## Self-Hosting
48
+
49
+
You can run your own PDS instance in the federated network! For source code and directions see the PDS distribution git repository [here](https://github.com/bluesky-social/pds).
+51
contextual info for claude/Firehose Bluesky.md
+51
contextual info for claude/Firehose Bluesky.md
···
1
+
---
2
+
title: "Firehose | Bluesky"
3
+
source: "https://docs.bsky.app/docs/advanced-guides/firehose"
4
+
author:
5
+
published:
6
+
created: 2025-03-07
7
+
description: "One of the core primitives of the AT Protocol that underlies Bluesky is the"
8
+
tags:
9
+
- "clippings"
10
+
---
11
+
One of the core primitives of the AT Protocol that underlies Bluesky is the *firehose*. It is an authenticated stream of events used to efficiently sync user updates (posts, likes, follows, handle changes, etc).
12
+
13
+
Many applications people will want to build on top of atproto and Bluesky will start with the firehose, from feed generators to labelers, to bots and search engines.
14
+
15
+
In the atproto ecosystem, there are many different endpoints that serve firehose APIs. Each PDS serves a stream of all of the activity on the repos it is responsible for. From there, *relays* aggregate the streams of any PDS who requests it into a single unified stream.
16
+
17
+
This makes the job of downstream consumers much easier, as you can get all the data from a single location. The main relay for Bluesky is `bsky.network`, which we use in the examples below.
18
+
19
+
To get started, you will open a WebSocket connection to your favorite firehose provider for the `com.atproto.sync.subscribeRepos` endpoint:
20
+
21
+
- Go
22
+
23
+
```prism
24
+
uri := "wss://bsky.network/xrpc/com.atproto.sync.subscribeRepos"
25
+
con, _, err := websocket.DefaultDialer.Dial(uri, http.Header{})
26
+
```
27
+
28
+
From there, you need to read off each message as it comes in, and decode the CBOR event data. More details on this can be found here (TODO: link to lexicon page).
29
+
30
+
Most SDKs have a nice wrapper for this though, In this example we will just print each repo operation in each event we receive. These operations are things like "create post", "create like", "delete follow" and so on.
31
+
32
+
- Go
33
+
34
+
```prism
35
+
rsc := &events.RepoStreamCallbacks{
36
+
RepoCommit: func(evt *atproto.SyncSubscribeRepos_Commit) error {
37
+
fmt.Println("Event from ", evt.Repo)
38
+
for _, op := range evt.Ops {
39
+
fmt.Printf(" - %s record %s\n", op.Action, op.Path)
40
+
}
41
+
return nil
42
+
},
43
+
}
44
+
45
+
sched := sequential.NewScheduler("myfirehose", rsc.EventHandler)
46
+
events.HandleRepoStream(context.Background(), con, sched)
47
+
```
48
+
49
+
In this snippet we set up a sequential "scheduler", which handles all events sequentially in order. Other schedulers run event handling in parallel, or do limited concurrency based on who the event is for.
50
+
51
+
Once we have a scheduler, we call into `HandleRepoStream` which does the actual decoding of the data coming over the websocket and calls into the event handler we wrote.
+367
contextual info for claude/Lexicon - AT Protocol 1.md
+367
contextual info for claude/Lexicon - AT Protocol 1.md
···
1
+
---
2
+
title: "Lexicon - AT Protocol"
3
+
source: "https://atproto.com/specs/lexicon"
4
+
author:
5
+
- "[[AT Protocol]]"
6
+
published:
7
+
created: 2025-03-07
8
+
description: "A schema definition language."
9
+
tags:
10
+
- "clippings"
11
+
---
12
+
Lexicon is a schema definition language used to describe atproto records, HTTP endpoints (XRPC), and event stream messages. It builds on top of the atproto [Data Model](https://atproto.com/specs/data-model).
13
+
14
+
The schema language is similar to [JSON Schema](http://json-schema.org/) and [OpenAPI](https://en.wikipedia.org/wiki/OpenAPI_Specification), but includes some atproto-specific features and semantics.
15
+
16
+
This specification describes version 1 of the Lexicon definition language.
17
+
18
+
| Lexicon Type | Data Model Type | Category |
19
+
| --- | --- | --- |
20
+
| `null` | Null | concrete |
21
+
| `boolean` | Boolean | concrete |
22
+
| `integer` | Integer | concrete |
23
+
| `string` | String | concrete |
24
+
| `bytes` | Bytes | concrete |
25
+
| `cid-link` | Link | concrete |
26
+
| `blob` | Blob | concrete |
27
+
| `array` | Array | container |
28
+
| `object` | Object | container |
29
+
| `params` | | container |
30
+
| `token` | | meta |
31
+
| `ref` | | meta |
32
+
| `union` | | meta |
33
+
| `unknown` | | meta |
34
+
| `record` | | primary |
35
+
| `query` | | primary |
36
+
| `procedure` | | primary |
37
+
| `subscription` | | primary |
38
+
39
+
Lexicons are JSON files associated with a single NSID. A file contains one or more definitions, each with a distinct short name. A definition with the name `main` optionally describes the "primary" definition for the entire file. A Lexicon with zero definitions is invalid.
40
+
41
+
A Lexicon JSON file is an object with the following fields:
42
+
43
+
- `lexicon` (integer, required): indicates Lexicon language version. In this version, a fixed value of `1`
44
+
- `id` (string, required): the NSID of the Lexicon
45
+
- `description` (string, optional): short overview of the Lexicon, usually one or two sentences
46
+
- `defs` (map of strings-to-objects, required): set of definitions, each with a distinct name (key)
47
+
48
+
Schema definitions under `defs` all have a `type` field to distinguish their type. A file can have at most one definition with one of the "primary" types. Primary types should always have the name `main`. It is possible for `main` to describe a non-primary type.
49
+
50
+
References to specific definitions within a Lexicon use fragment syntax, like `com.example.defs#someView`. If a `main` definition exists, it can be referenced without a fragment, just using the NSID. For references in the `$type` fields in data objects themselves (eg, records or contents of a union), this is a "must" (use of a `#main` suffix is invalid). For example, `com.example.record` not `com.example.record#main`.
51
+
52
+
Related Lexicons are often grouped together in the NSID hierarchy. As a convention, any definitions used by multiple Lexicons are defined in a dedicated `*.defs` Lexicon (eg, `com.atproto.server.defs`) within the group. A `*.defs` Lexicon should generally not include a definition named `main`, though it is not strictly invalid to do so.
53
+
54
+
The primary types are:
55
+
56
+
- `query`: describes an XRPC Query (HTTP GET)
57
+
- `procedure`: describes an XRPC Procedure (HTTP POST)
58
+
- `subscription`: Event Stream (WebSocket)
59
+
- `record`: describes an object that can be stored in a repository record
60
+
61
+
Each primary definition schema object includes these fields:
62
+
63
+
- `type` (string, required): the type value (eg, `record` for records)
64
+
- `description` (string, optional): short, usually only a sentence or two
65
+
66
+
### Record
67
+
68
+
Type-specific fields:
69
+
70
+
- `key` (string, required): specifies the [Record Key type](https://atproto.com/specs/record-key)
71
+
- `record` (object, required): a schema definition with type `object`, which specifies this type of record
72
+
73
+
### Query and Procedure (HTTP API)
74
+
75
+
Type-specific fields:
76
+
77
+
- `parameters` (object, optional): a schema definition with type `params`, describing the HTTP query parameters for this endpoint
78
+
- `output` (object, optional): describes the HTTP response body
79
+
- `description` (string, optional): short description
80
+
- `encoding` (string, required): MIME type for body contents. Use `application/json` for JSON responses.
81
+
- `schema` (object, optional): schema definition, either an `object`, a `ref`, or a `union` of refs. Used to describe JSON encoded responses, though schema is optional even for JSON responses.
82
+
- `input` (object, optional, only for `procedure`): describes HTTP request body schema, with the same format as the `output` field
83
+
- `errors` (array of objects, optional): set of string error codes which might be returned
84
+
- `name` (string, required): short name for the error type, with no whitespace
85
+
- `description` (string, optional): short description, one or two sentences
86
+
87
+
### Subscription (Event Stream)
88
+
89
+
Type-specific fields:
90
+
91
+
- `parameters` (object, optional): same as Query and Procedure
92
+
- `message` (object, optional): specifies what messages can be
93
+
- `description` (string, optional): short description
94
+
- `schema` (object, required): schema definition, which must be a `union` of refs
95
+
- `errors` (array of objects, optional): same as Query and Procedure
96
+
97
+
Subscription schemas (referenced by the `schema` field under `message`) must be a `union` of refs, not an `object` type.
98
+
99
+
As with the primary definitions, every schema object includes these fields:
100
+
101
+
- `type` (string, required): fixed value for each type
102
+
- `description` (string, optional): short, usually only a sentence or two
103
+
104
+
### `null`
105
+
106
+
No additional fields.
107
+
108
+
### `boolean`
109
+
110
+
Type-specific fields:
111
+
112
+
- `default` (boolean, optional): a default value for this field
113
+
- `const` (boolean, optional): a fixed (constant) value for this field
114
+
115
+
When included as an HTTP query parameter, should be rendered as `true` or `false` (no quotes).
116
+
117
+
### `integer`
118
+
119
+
A signed integer number.
120
+
121
+
Type-specific fields:
122
+
123
+
- `minimum` (integer, optional): minimum acceptable value
124
+
- `maximum` (integer, optional): maximum acceptable value
125
+
- `enum` (array of integers, optional): a closed set of allowed values
126
+
- `default` (integer, optional): a default value for this field
127
+
- `const` (integer, optional): a fixed (constant) value for this field
128
+
129
+
### `string`
130
+
131
+
Type-specific fields:
132
+
133
+
- `format` (string, optional): string format restriction
134
+
- `maxLength` (integer, optional): maximum length of value, in UTF-8 bytes
135
+
- `minLength` (integer, optional): minimum length of value, in UTF-8 bytes
136
+
- `maxGraphemes` (integer, optional): maximum length of value, counted as Unicode Grapheme Clusters
137
+
- `minGraphemes` (integer, optional): minimum length of value, counted as Unicode Grapheme Clusters
138
+
- `knownValues` (array of strings, optional): a set of suggested or common values for this field. Values are not limited to this set (aka, not a closed enum).
139
+
- `enum` (array of strings, optional): a closed set of allowed values
140
+
- `default` (string, optional): a default value for this field
141
+
- `const` (string, optional): a fixed (constant) value for this field
142
+
143
+
Strings are Unicode. For non-Unicode encodings, use `bytes` instead. The basic `minLength`/`maxLength` validation constraints are counted as UTF-8 bytes. Note that Javascript stores strings with UTF-16 by default, and it is necessary to re-encode to count accurately. The `minGraphemes`/`maxGraphemes` validation constraints work with Grapheme Clusters, which have a complex technical and linguistic definition, but loosely correspond to "distinct visual characters" like Latin letters, CJK characters, punctuation, digits, or emoji (which might comprise multiple Unicode codepoints and many UTF-8 bytes).
144
+
145
+
`format` constrains the string format and provides additional semantic context. Refer to the Data Model specification for the available format types and their definitions.
146
+
147
+
`const` and `default` are mutually exclusive.
148
+
149
+
### `bytes`
150
+
151
+
Type-specific fields:
152
+
153
+
- `minLength` (integer, optional): minimum size of value, as raw bytes with no encoding
154
+
- `maxLength` (integer, optional): maximum size of value, as raw bytes with no encoding
155
+
156
+
### `cid-link`
157
+
158
+
No type-specific fields.
159
+
160
+
See [Data Model spec](https://atproto.com/specs/data-model) for CID restrictions.
161
+
162
+
### `array`
163
+
164
+
Type-specific fields:
165
+
166
+
- `items` (object, required): describes the schema elements of this array
167
+
- `minLength` (integer, optional): minimum count of elements in array
168
+
- `maxLength` (integer, optional): maximum count of elements in array
169
+
170
+
In theory arrays have homogeneous types (meaning every element as the same type). However, with union types this restriction is meaningless, so implementations can not assume that all the elements have the same type.
171
+
172
+
### `object`
173
+
174
+
A generic object schema which can be nested inside other definitions by reference.
175
+
176
+
Type-specific fields:
177
+
178
+
- `properties` (map of strings-to-objects, required): defines the properties (fields) by name, each with their own schema
179
+
- `required` (array of strings, optional): indicates which properties are required
180
+
- `nullable` (array of strings, optional): indicates which properties can have `null` as a value
181
+
182
+
As described in the data model specification, there is a semantic difference in data between omitting a field; including the field with the value `null`; and including the field with a "false-y" value (`false`, `0`, empty array, etc).
183
+
184
+
### `blob`
185
+
186
+
Type-specific fields:
187
+
188
+
- `accept` (array of strings, optional): list of acceptable MIME types. Each may end in `*` as a glob pattern (eg, `image/*`). Use `*/*` to indicate that any MIME type is accepted.
189
+
- `maxSize` (integer, optional): maximum size in bytes
190
+
191
+
### `params`
192
+
193
+
This is a limited-scope type which is only ever used for the `parameters` field on `query`, `procedure`, and `subscription` primary types. These map to HTTP query parameters.
194
+
195
+
Type-specific fields:
196
+
197
+
- `required` (array of strings, optional): same semantics as field on `object`
198
+
- `properties`: similar to properties under `object`, but can only include the types `boolean`, `integer`, `string`, and `unknown`; or an `array` of one of these types
199
+
200
+
Note that unlike `object`, there is no `nullable` field on `params`.
201
+
202
+
### `token`
203
+
204
+
Tokens are empty data values which exist only to be referenced by name. They are used to define a set of values with specific meanings. The `description` field should clarify the meaning of the token. Tokens encode as string data, with the string being the fully-qualified reference to the token itself (NSID followed by an optional fragment).
205
+
206
+
Tokens are similar to the concept of a "symbol" in some programming languages, distinct from strings, variables, built-in keywords, or other identifiers.
207
+
208
+
For example, tokens could be defined to represent the state of an entity (in a state machine), or to enumerate a list of categories.
209
+
210
+
No type-specific fields.
211
+
212
+
### `ref`
213
+
214
+
Type-specific fields:
215
+
216
+
- `ref` (string, required): reference to another schema definition
217
+
218
+
Refs are a mechanism for re-using a schema definition in multiple places. The `ref` string can be a global reference to a Lexicon type definition (an NSID, optionally with a `#`\-delimited name indicating a definition other than `main`), or can indicate a local definition within the same Lexicon file (a `#` followed by a name).
219
+
220
+
### `union`
221
+
222
+
Type-specific fields:
223
+
224
+
- `refs` (array of strings, required): references to schema definitions
225
+
- `closed` (boolean, optional): indicates if a union is "open" or "closed". defaults to `false` (open union)
226
+
227
+
Unions represent that multiple possible types could be present at this location in the schema. The references follow the same syntax as `ref`, allowing references to both global or local schema definitions. Actual data will validate against a single specific type: the union does not *combine* fields from multiple schemas, or define a new *hybrid* data type. The different types are referred to as **variants**.
228
+
229
+
By default unions are "open", meaning that future revisions of the schema could add more types to the list of refs (though can not remove types). This means that implementations should be permissive when validating, in case they do not have the most recent version of the Lexicon. The `closed` flag (boolean) can indicate that the set of types is fixed and can not be extended in the future.
230
+
231
+
A `union` schema definition with no `refs` is allowed and similar to `unknown`, as long as the `closed` flag is false (the default). The main difference is that the data would be required to have the `$type` field. An empty refs list with `closed` set to true is an invalid schema.
232
+
233
+
The schema definitions pointed to by a `union` are objects or types with a clear mapping to an object, like a `record`. All the variants must be represented by a CBOR map (or JSON Object) and must include a `$type` field indicating the variant type. Because the data must be an object, unions can not reference `token` (which would correspond to string data).
234
+
235
+
### `unknown`
236
+
237
+
Indicates than any data object could appear at this location, with no specific validation. The top-level data must be an object (not a string, boolean, etc). As with all other data types, the value `null` is not allowed unless the field is specifically marked as `nullable`.
238
+
239
+
The data object may contain a `$type` field indicating the schema of the data, but this is not currently required. The top-level data object must not have the structure of a compound data type, like blob (`$type: blob`) or CID link (`$link`).
240
+
241
+
The (nested) contents of the data object must still be valid under the atproto data model. For example, it should not contain floats. Nested compound types like blobs and CID links should be validated and transformed as expected.
242
+
243
+
Lexicon designers are strongly recommended to not use `unknown` fields in `record` objects for now.
244
+
245
+
No type-specific fields.
246
+
247
+
Strings can optionally be constrained to one of the following `format` types:
248
+
249
+
- `at-identifier`: either a [Handle](https://atproto.com/specs/handle) or a [DID](https://atproto.com/specs/did), details described below
250
+
- `at-uri`: [AT-URI](https://atproto.com/specs/at-uri-scheme)
251
+
- `cid`: CID in string format, details specified in [Data Model](https://atproto.com/specs/data-model)
252
+
- `datetime`: timestamp, details specified below
253
+
- `did`: generic [DID Identifier](https://atproto.com/specs/did)
254
+
- `handle`: [Handle Identifier](https://atproto.com/specs/handle)
255
+
- `nsid`: [Namespaced Identifier](https://atproto.com/specs/nsid)
256
+
- `tid`: [Timestamp Identifier (TID)](https://atproto.com/specs/tid)
257
+
- `record-key`: [Record Key](https://atproto.com/specs/record-key), matching the general syntax ("any")
258
+
- `uri`: generic URI, details specified below
259
+
- `language`: language code, details specified below
260
+
261
+
For the various identifier formats, when doing Lexicon schema validation the most expansive identifier syntax format should be permitted. Problems with identifiers which do pass basic syntax validation should be reported as application errors, not lexicon data validation errors. For example, data with any kind of DID in a `did` format string field should pass Lexicon validation, with unsupported DID methods being raised separately as an application error.
262
+
263
+
### `at-identifier`
264
+
265
+
A string type which is either a DID (type: did) or a handle (handle). Mostly used in XRPC query parameters. It is unambiguous whether an at-identifier is a handle or a DID because a DID always starts with did:, and the colon character (:) is not allowed in handles.
266
+
267
+
### `datetime`
268
+
269
+
Full-precision date and time, with timezone information.
270
+
271
+
This format is intended for use with computer-generated timestamps in the modern computing era (eg, after the UNIX epoch). If you need to represent historical or ancient events, ambiguity, or far-future times, a different format is probably more appropriate. Datetimes before the Current Era (year zero) as specifically disallowed.
272
+
273
+
Datetime format standards are notoriously flexible and overlapping. Datetime strings in atproto should meet the [intersecting](https://ijmacd.github.io/rfc3339-iso8601/) requirements of the [RFC 3339](https://www.rfc-editor.org/rfc/rfc3339), [ISO 8601](https://en.wikipedia.org/wiki/ISO_8601), and [WHATWG HTML](https://html.spec.whatwg.org/#dates-and-times) datetime standards.
274
+
275
+
The character separating "date" and "time" parts must be an upper-case `T`.
276
+
277
+
Timezone specification is required. It is *strongly* preferred to use the UTC timezone, and to represent the timezone with a simple capital `Z` suffix (lower-case is not allowed). While hour/minute suffix syntax (like `+01:00` or `-10:30`) is supported, "negative zero" (`-00:00`) is specifically disallowed (by ISO 8601).
278
+
279
+
Whole seconds precision is required, and arbitrary fractional precision digits are allowed. Best practice is to use at least millisecond precision, and to pad with zeros to the generated precision (eg, trailing `:12.340Z` instead of `:12.34Z`). Not all datetime formatting libraries support trailing zero formatting. Both millisecond and microsecond precision have reasonable cross-language support; nanosecond precision does not.
280
+
281
+
Implementations should be aware when round-tripping records containing datetimes of two ambiguities: loss-of-precision, and ambiguity with trailing fractional second zeros. If de-serializing Lexicon records into native types, and then re-serializing, the string representation may not be the same, which could result in broken hash references, sanity check failures, or repository update churn. A safer thing to do is to deserialize the datetime as a simple string, which ensures round-trip re-serialization.
282
+
283
+
Implementations "should" validate that the semantics of the datetime are valid. For example, a month or day `00` is invalid.
284
+
285
+
Valid examples:
286
+
287
+
Invalid examples:
288
+
289
+
### `uri`
290
+
291
+
Flexible to any URI schema, following the generic RFC-3986 on URIs. This includes, but isn’t limited to: `did`, `https`, `wss`, `ipfs` (for CIDs), `dns`, and of course `at`. Maximum length in Lexicons is 8 KBytes.
292
+
293
+
### `language`
294
+
295
+
An [IETF Language Tag](https://en.wikipedia.org/wiki/IETF_language_tag) string, compliant with [BCP 47](https://www.rfc-editor.org/info/bcp47), defined in [RFC 5646](https://www.rfc-editor.org/rfc/rfc5646.txt) ("Tags for Identifying Languages"). This is the same standard used to identify languages in HTTP, HTML, and other web standards. The Lexicon string must validate as a "well-formed" language tag, as defined in the RFC. Clients should ignore language strings which are "well-formed" but not "valid" according to the RFC.
296
+
297
+
As specified in the RFC, ISO 639 two-character and three-character language codes can be used on their own, lower-cased, such as `ja` (Japanese) or `ban` (Balinese). Regional sub-tags can be added, like `pt-BR` (Brazilian Portuguese). Additional subtags can also be added, such as `hy-Latn-IT-arevela`.
298
+
299
+
Language codes generally need to be parsed, normalized, and matched semantically, not simply string-compared. For example, a search engine might simplify language tags to ISO 639 codes for indexing and filtering, while a client application (user agent) would retain the full language code for presentation (text rendering) locally.
300
+
301
+
Data objects sometimes include a `$type` field which indicates their Lexicon type. The general principle is that this field needs to be included any time there could be ambiguity about the content type when validating data.
302
+
303
+
The specific rules are:
304
+
305
+
- `record` objects must always include `$type`. While the type is often known from context (eg, the collection part of the path for records stored in a repository), record objects can also be passed around outside of repositories and need to be self-describing
306
+
- `union` variants must always include `$type`, except at the top level of `subscription` messages
307
+
308
+
Note that `blob` objects always include `$type`, which allows generic processing.
309
+
310
+
As a reminder, `main` types must be referenced in `$type` fields as just the NSID, not including a `#main` suffix.
311
+
312
+
Lexicons are allowed to change over time, within some bounds to ensure both forwards and backwards compatibility. The basic principle is that all old data must still be valid under the updated Lexicon, and new data must be valid under the old Lexicon.
313
+
314
+
- Any new fields must be optional
315
+
- Non-optional fields can not be removed. A best practice is to retain all fields in the Lexicon and mark them as deprecated if they are no longer used.
316
+
- Types can not change
317
+
- Fields can not be renamed
318
+
319
+
If larger breaking changes are necessary, a new Lexicon name must be used.
320
+
321
+
It can be ambiguous when a Lexicon has been published and becomes "set in stone". At a minimum, public adoption and implementation by a third party, even without explicit permission, indicates that the Lexicon has been released and should not break compatibility. A best practice is to clearly indicate in the Lexicon type name any experimental or development status. Eg, `com.corp.experimental.newRecord`.
322
+
323
+
The authority for a Lexicon is determined by the NSID, and rooted in DNS control of the domain authority. That authority has ultimate control over the Lexicon definition, and responsibility for maintenance and distribution of Lexicon schema definitions.
324
+
325
+
In a crisis, such as unintentional loss of DNS control to a bad actor, the protocol ecosystem could decide to disregard this chain of authority. This should only be done in exceptional circumstances, and not as a mechanism to subvert an active authority. The primary mechanism for resolving protocol disputes is to fork Lexicons in to a new namespace.
326
+
327
+
Protocol implementations should generally consider data which fails to validate against the Lexicon to be entirely invalid, and should not try to repair or do partial processing on the individual piece of data.
328
+
329
+
Unexpected fields in data which otherwise conforms to the Lexicon should be ignored. When doing schema validation, they should be treated at worst as warnings. This is necessary to allow evolution of the schema by the controlling authority, and to be robust in the case of out-of-date Lexicons.
330
+
331
+
Third parties can technically insert any additional fields they want into data. This is not the recommended way to extend applications, but it is not specifically disallowed. One danger with this is that the Lexicon may be updated to include fields with the same field names but different types, which would make existing data invalid.
332
+
333
+
Lexicon schemas are published publicly as records in atproto repositories, using the `com.atproto.lexicon.schema` type. The domain name authority for [NSIDs](https://atproto.com/specs/nsid) to specific atproto repositories (identified by [DID](https://atproto.com/specs/did) is linked by a DNS TXT record (`_lexicon`), similar to but distinct from the [handle resolution](https://atproto.com/specs/handle) system.
334
+
335
+
The `com.atproto.lexicon.schema` Lexicon itself is very minimal: it only requires the `lexicon` integer field, which must be `1` for this version of the Lexicon language. In practice, same fields as [Lexicon Files](https://atproto.com/specs/#lexicon-files) should be included, along with `$type`. The record key is the NSID of the schema.
336
+
337
+
A summary of record fields:
338
+
339
+
- `$type`: must be `com.atproto.lexicon.schema` (as with all atproto records)
340
+
- `lexicon`: integer, indicates the overall version of the Lexicon (currently `1`)
341
+
- `id`: the NSID of this Lexicon. Must be a simple NSID (no fragment), and must match the record key
342
+
- `defs`: the schema definitions themselves, as a map-of-objects. Names should not include a `#` prefix.
343
+
- `description`: optional description of the overall schema; though descriptions are best included on individual defs, not the overall schema.
344
+
345
+
The `com.atproto.lexicon.schema` meta-schema is somewhat unlike other Lexicons, in that it is defined and governed as part of the protocol. Future versions of the language and protocol might not follow the evolution rules. It is an intentional decision to not express the Lexicon schema language itself recursively, using the schema language.
346
+
347
+
Authority for NSID namespaces is done at the "group" level, meaning that all NSIDs which differ only by the final "name" part are all published in the same repository. Lexicon resolution of NSIDs is not hierarchical: DNS TXT records must be created for each authority section, and resolvers should not recurse up or down the DNS hierarchy looking for TXT records.
348
+
349
+
As an example, the NSID `edu.university.dept.lab.blogging.getBlogPost` has a "name" `getBlogPost`. Removing the name and reversing the rest of the NSID gives an "authority domain name" of `blogging.lab.dept.university.edu`. To link the authority to a specific DID (say `did:plc:ewvi7nxzyoun6zhxrhs64oiz`), a DNS TXT record with the name `_lexicon.blogging.lab.dept.university.edu` and value `did=did:plc:ewvi7nxzyoun6zhxrhs64oiz` (note the `did=` prefix) would be created. Then a record with collection `com.atproto.lexicon.schema` and record-key `edu.university.dept.lab.blogging.getBlogPost` would be created in that account's repository.
350
+
351
+
A resolving service would start with the NSID (`edu.university.dept.lab.blogging.getBlogPost`) and do a DNS TXT resolution for `_lexicon.blogging.lab.dept.university.edu`. Finding the DID, it would proceed with atproto DID resolution, look for a PDS, and then fetch the relevant record. The overall AT-URI for the record would be `at://did:plc:ewvi7nxzyoun6zhxrhs64oiz/com.atproto.lexicon.schema/edu.university.dept.lab.blogging.getBlogPost`.
352
+
353
+
If the DNS TXT resolution for `_lexicon.blogging.lab.dept.university.edu` failed, the resolving service would *NOT* try `_lexicon.lab.dept.university.edu` or `_lexicon.getBlogPost.blogging.lab.dept.university.edu` or `_lexicon.university.edu`, or any other domain name. The Lexicon resolution would simply fail.
354
+
355
+
If another NSID `edu.university.dept.lab.blogging.getBlogComments` was created, it would have the same authority name, and must be published in the same atproto repository (with a different record key). If a Lexicon for `edu.university.dept.lab.gallery.photo` was published, a new DNS TXT record would be required (`_lexicon.gallery.lab.dept.university.edu`; it could point at the same repository (DID), or a different repository.
356
+
357
+
As a simpler example, an NSID `app.toy.record` would resolve via `_lexicon.toy.app`.
358
+
359
+
A single repository can host Lexicons for multiple authority domains, possibly across multiple registered domains and TLDs. Resolution DNS records can change over time, moving schema resolution to different repositories, though it may take time for DNS and cache changes to propagate.
360
+
361
+
Note that Lexicon record operations are broadcast over repository event streams ("firehose"), but that DNS resolution changes do not (unlike handle changes). Resolving services should not cache DNS resolution results for long time periods.
362
+
363
+
It should be possible to translate Lexicon schemas to JSON Schema or OpenAPI and use tools and libraries from those ecosystems to work with atproto data in JSON format.
364
+
365
+
Implementations which serialize and deserialize data from JSON or CBOR into structures derived from specific Lexicons should be aware of the risk of "clobbering" unexpected fields. For example, if a Lexicon is updated to add a new (optional) field, old implementations would not be aware of that field, and might accidentally strip the data when de-serializing and then re-serializing. Depending on the context, one way to avoid this problem is to retain any "extra" fields, or to pass-through the original data object instead of re-serializing it.
366
+
367
+
The validation rules for unexpected additional fields may change. For example, a mechanism for Lexicons to indicate that the schema is "closed" and unexpected fields are not allowed, or a convention around field name prefixes (`x-`) to indicate unofficial extension.
+60
contextual info for claude/Lexicon - AT Protocol.md
+60
contextual info for claude/Lexicon - AT Protocol.md
···
1
+
---
2
+
title: "Lexicon - AT Protocol"
3
+
source: "https://atproto.com/guides/lexicon"
4
+
author:
5
+
- "[[AT Protocol]]"
6
+
published:
7
+
created: 2025-03-07
8
+
description: "A schema-driven interoperability framework"
9
+
tags:
10
+
- "clippings"
11
+
---
12
+
## Intro to Lexicon
13
+
14
+
Lexicon is a schema system used to define RPC methods and record types. Every Lexicon schema is written in JSON, in a format similar to [JSON-Schema](https://json-schema.org/) for defining constraints.
15
+
16
+
The schemas are identified using [NSIDs](https://atproto.com/specs/nsid) which are a reverse-DNS format. Here are some example API endpoints:
17
+
18
+
And here are some example record types:
19
+
20
+
The schema types, definition language, and validation constraints are described in the [Lexicon specification](https://atproto.com/specs/lexicon), and representations in JSON and CBOR are described in the [Data Model specification](https://atproto.com/specs/data-model).
21
+
22
+
**Interoperability.** An open network like atproto needs a way to agree on behaviors and semantics. Lexicon solves this while making it relatively simple for developers to introduce new schemas.
23
+
24
+
**Lexicon is not RDF.** While RDF is effective at describing data, it is not ideal for enforcing schemas. Lexicon is easier to use because it doesn't need the generality that RDF provides. In fact, Lexicon's schemas enable code-generation with types and validation, which makes life much easier!
25
+
26
+
The AT Protocol's API system, [XRPC](https://atproto.com/specs/xrpc), is essentially a thin wrapper around HTTPS. For example, a call to:
27
+
28
+
is actually just an HTTP request:
29
+
30
+
The schemas establish valid query parameters, request bodies, and response bodies.
31
+
32
+
With code-generation, these schemas become very easy to use:
33
+
34
+
Schemas define the possible values of a record. Every record has a "type" which maps to a schema and also establishes the URL of a record.
35
+
36
+
For instance, this "follow" record:
37
+
38
+
...would have a URL like:
39
+
40
+
...and a schema like:
41
+
42
+
Tokens declare global identifiers which can be used in data.
43
+
44
+
Let's say a record schema wanted to specify three possible states for a traffic light: 'red', 'yellow', and 'green'.
45
+
46
+
This is perfectly acceptable, but it's not extensible. You could never add new states, like "flashing yellow" or "purple" (who knows, it could happen).
47
+
48
+
To add flexibility, you could remove the enum constraint and just document the possible values:
49
+
50
+
This isn't bad, but it lacks specificity. People inventing new values for state are likely to collide with each other, and there won't be clear documentation on each state.
51
+
52
+
Instead, you can define Lexicon tokens for the values you use:
53
+
54
+
This gives us unambiguous values to use in our trafficLight state. The final schema will still use flexible validation, but other teams will have more clarity on where the values originate from and how to add their own:
55
+
56
+
Once a schema is published, it can never change its constraints. Loosening a constraint (adding possible values) will cause old software to fail validation for new data, and tightening a constraint (removing possible values) will cause new software to fail validation for old data. As a consequence, schemas may only add optional constraints to previously unconstrained fields.
57
+
58
+
If a schema must change a previously-published constraint, it should be published as a new schema under a new NSID.
59
+
60
+
Schemas are designed to be machine-readable and network-accessible. While it is not currently *required* that a schema is available on the network, it is strongly advised to publish schemas so that a single canonical & authoritative representation is available to consumers of the method.
+77
contextual info for claude/Namespaced Identifiers (NSIDs) - AT Protocol.md
+77
contextual info for claude/Namespaced Identifiers (NSIDs) - AT Protocol.md
···
1
+
---
2
+
title: "Namespaced Identifiers (NSIDs) - AT Protocol"
3
+
source: "https://atproto.com/specs/nsid"
4
+
author:
5
+
- "[[AT Protocol]]"
6
+
published:
7
+
created: 2025-03-07
8
+
description: "A specification for global semantic IDs."
9
+
tags:
10
+
- "clippings"
11
+
---
12
+
Namespaced Identifiers (NSIDs) are used to reference Lexicon schemas for records, XRPC endpoints, and more.
13
+
14
+
The basic structure and semantics of an NSID are a fully-qualified hostname in Reverse Domain-Name Order, followed by a simple name. The hostname part is the **domain authority,** and the final segment is the **name**.
15
+
16
+
### NSID Syntax
17
+
18
+
Lexicon string type: `nsid`
19
+
20
+
The domain authority part of an NSID must be a valid handle with the order of segments reversed. That is followed by a name segment which must be an ASCII camel-case string.
21
+
22
+
For example, `com.example.fooBar` is a syntactically valid NSID, where `com.example` is the domain authority, and `fooBar` is the name segment.
23
+
24
+
The comprehensive list of syntax rules is:
25
+
26
+
- Overall NSID:
27
+
- must contain only ASCII characters
28
+
- separate the domain authority and the name by an ASCII period character (`.`)
29
+
- must have at least 3 segments
30
+
- can have a maximum total length of 317 characters
31
+
- Domain authority:
32
+
- made of segments separated by periods (`.`)
33
+
- at most 253 characters (including periods), and must contain at least two segments
34
+
- each segment must have at least 1 and at most 63 characters (not including any periods)
35
+
- the allowed characters are ASCII letters (`a-z`), digits (`0-9`), and hyphens (`-`)
36
+
- segments can not start or end with a hyphen
37
+
- the first segment (the top-level domain) can not start with a numeric digit
38
+
- the domain authority is not case-sensitive, and should be normalized to lowercase (that is, normalize ASCII `A-Z` to `a-z`)
39
+
- Name:
40
+
- must have at least 1 and at most 63 characters
41
+
- the allowed characters are ASCII letters only (`A-Z`, `a-z`)
42
+
- digits and hyphens are not allowed
43
+
- case-sensitive and should not be normalized
44
+
45
+
A reference regex for NSID is:
46
+
47
+
### NSID Syntax Variations
48
+
49
+
A **fragment** may be appended to an NSID in some contexts to refer to a specific sub-field within the schema. The fragment is separated from the NSID by an ASCII hash character (`#`). The fragment identifier string (after the `#`) has the same syntax restrictions as the final segment of an NSID: ASCII alphabetic, one or more characters, length restricted, etc.
50
+
51
+
When referring to a group or pattern of NSIDs, a trailing ASCII star character (`*`) can be used as a "glob" character. For example, `com.atproto.*` would refer to any NSIDs under the `atproto.com` domain authority, including nested sub-domains (sub-authorities). A free-standing `*` would match all NSIDs from all authorities. Currently, there may be only a single start character; it must be the last character; and it must be at a segment boundary (no partial matching of segment names). This means the start character must be proceeded by a period, or be a bare star matching all NSIDs.
52
+
53
+
### Examples
54
+
55
+
Syntactically valid NSIDs:
56
+
57
+
Invalid NSIDs:
58
+
59
+
### Usage and Implementation Guidelines
60
+
61
+
A **strongly-encouraged** best practice is to use authority domains with only ASCII alphabetic characters (that is, no digits or hyphens). This makes it significantly easier to generate client libraries in most programming languages.
62
+
63
+
The overall NSID is case-sensitive for display, storage, and validation. However, having multiple NSIDs that differ only by casing is not allowed. Namespace authorities are responsible for preventing duplication and confusion. Implementations should not force-lowercase NSIDs.
64
+
65
+
It is common to use "subdomains" as part of the "domain authority" to organize related NSIDs. For example, the NSID `com.atproto.sync.getHead` uses the `sync` segment. Note that this requires control of the full domain `sync.atproto.com`, in addition to the domain `atproto.com`.
66
+
67
+
Lexicon language documentation will provide style guidelines on choosing and organizing NSIDs for both record types and XRPC methods. In short, records are usually single nouns, not pluralized. XRPC methods are usually in "verbNoun" form.
68
+
69
+
### Possible Future Changes
70
+
71
+
It is conceivable that NSID syntax would be relaxed to allow Unicode characters in the final segment.
72
+
73
+
The "glob" syntax variation may be modified to extended to make the distinction between single-level and nested matching more explicit.
74
+
75
+
The "fragment" syntax variation may be relaxed in the future to allow nested references.
76
+
77
+
No automated mechanism for verifying control of a "domain authority" currently exists. Also, not automated mechanism exists for fetching a lexicon schema for a given NSID, or for enumerating all NSIDs for a base domain.
+365
contextual info for claude/OAuth - AT Protocol.md
+365
contextual info for claude/OAuth - AT Protocol.md
···
1
+
---
2
+
title: "OAuth - AT Protocol"
3
+
source: "https://atproto.com/specs/oauth"
4
+
author:
5
+
- "[[AT Protocol]]"
6
+
published:
7
+
created: 2025-03-07
8
+
description: "OAuth for Client/Server Authentication and Authorization"
9
+
tags:
10
+
- "clippings"
11
+
---
12
+
The OAuth profile for atproto is new and may be revised based on feedback from the development community and ongoing standards work. Read more about the rollout in the [OAuth Roadmap](https://github.com/bluesky-social/atproto/discussions/2656).
13
+
14
+
This specification is authoritative, but is not an implementation guide and does not provide much background or context around design decisions. The earlier [design proposal](https://github.com/bluesky-social/proposals/tree/main/0004-oauth) is not authoritative but provides more context and examples. SDK documentation and the [client implementation guide](https://docs.bsky.app/docs/advanced-guides/oauth-client) are more approachable for developers.
15
+
16
+
OAuth is the primary mechanism in atproto for clients to make authorized requests to PDS instances. Most user-facing software is expected to use OAuth, including "front-end" clients like mobile apps, rich browser apps, or native desktop apps, as well as "back-end" clients like web services.
17
+
18
+
See the [HTTP API specification](https://atproto.com/specs/xrpc) for other forms of auth in atproto, including legacy HTTP client sessions/tokens, and inter-service auth.
19
+
20
+
OAuth is a constantly evolving framework of standards and best practices, standardized by the IETF. atproto uses a specific "profile" of OAuth which mandates a particular combination of OAuth standards, as described in this document.
21
+
22
+
At a high level, we start with the "OAuth 2.1" ([`draft-ietf-oauth-v2-1`](https://datatracker.ietf.org/doc/draft-ietf-oauth-v2-1/)) evolution of OAuth 2.0, which means:
23
+
24
+
- only the "authorization code" OAuth 2.0 grant type is supported, not "implicit" or other grant types
25
+
- mandatory Proof Key for Code Exchange (PKCE, [RFC 7636](https://datatracker.ietf.org/doc/html/rfc7636))
26
+
- security best practices ([`draft-ietf-oauth-security-topics`](https://datatracker.ietf.org/doc/html/draft-ietf-oauth-security-topics) and [`draft-ietf-oauth-browser-based-apps`](https://datatracker.ietf.org/doc/html/draft-ietf-oauth-browser-based-apps)) are required
27
+
28
+
Unlike a centralized app platform, in atproto there are many independent server implementations, so server discovery and client registration are automated using a combination of public auth server metadata and public client metadata. The `client_id` is a fully-qualified web URL pointing to the public client metadata (JSON document). There is no `client_secret` shared between servers and clients. When initiating a login with a handle or DID, an atproto-specific identity resolution step is required to discover the account’s PDS network location.
29
+
30
+
In OAuth terminology, an atproto Personal Data Server (PDS) is a "Resource Server" to which authorized HTTP requests are made using access tokens. Sometimes the PDS is also the "Authorization Server" - which services OAuth authorization flows and token requests - while in other situations a separate "entryway" service acts as the Authorization Server for multiple PDS instances. Clients from a metadata file from the PDS to discover the Authorization Server network location.
31
+
32
+
DPoP (with mandatory server issued nonces) is required to bind auth tokens to specific client software instances (eg, end devices or browser sessions). Pushed Authentication Requests (PAR) are used to streamline the authorization request flow. "Confidential" clients use JWTs signed with a secret key to authenticate the client software to Authorization Servers when making authorization requests.
33
+
34
+
Automated client registration using client metadata is one of the more novel aspects of OAuth in atproto. As of August 2024, client metadata is still an Internet Draft ([`draft-parecki-oauth-client-id-metadata-document`](https://datatracker.ietf.org/doc/draft-parecki-oauth-client-id-metadata-document/)); it should not be confused with the existing "Dynamic Client Registration" standard ([RFC 7591](https://datatracker.ietf.org/doc/html/rfc7591)). We are hopeful other open protocols will adopt similar automated registration flows in the future, but there may not be general OAuth ecosystem support for some time.
35
+
36
+
OAuth 2.0 is traditionally an authorization (`authz`) system, not an authentication (`authn`) system, meaning that it is not always a solution for pure account authentication use cases, such as "Signup/Login with XYZ" identity integrations. OpenID Connect (OIDC), which builds on top of OAuth 2.0, is usually the recommended standard for identity authentication. Unfortunately, the current version of OIDC does not enable authentication of atproto identities in a secure and generic way. The atproto profile of OAuth includes a (mandatory) mechanism for account authentication during the authorization flow and can be used for atproto identity authentication use cases.
37
+
38
+
This section describes requirements for OAuth clients, which are enforced by Authorization Servers.
39
+
40
+
OAuth client software is identified by a globally unique `client_id`. Distinct variants of client software may have distinct `client_id` values; for example the browser app and Android (mobile OS) variants of the same software might have different `client_id` values. As required by the [`draft-parecki-oauth-client-id-metadata-document`](https://datatracker.ietf.org/doc/draft-parecki-oauth-client-id-metadata-document) specification draft, the `client_id` must be a fully-qualified web URL from which the client-metadata JSON document can be fetched. For example, `https://app.example.com/client-metadata.json`. Some more about the `client_id`:
41
+
42
+
- it must be a well-formed URL, following the W3C URL specification
43
+
- the schema must be `https://`, and there must not be a port number included. Note that there is a special exception for `http://localhost` `client_id` values for development, see details below
44
+
- the path does not need to include `client-metadata.json`, but it is helpful convention
45
+
46
+
Authorization Servers which support both the atproto OAuth profile and other forms of OAuth should take care to prevent `client_id` value collisions. For example, `client_id` values for clients which are not auto-registered should never have the prefix `https://` or `http://`.
47
+
48
+
### Types of Clients
49
+
50
+
All atproto OAuth clients need to meet a core set of standards and requirements, but there are a few variations in capabilities (such as session lifetime) depending on the security properties of the client itself.
51
+
52
+
As described in the OAuth 2.0 specification ([RFC 6749](https://datatracker.ietf.org/doc/html/rfc6749)), every client is one of two broad types:
53
+
54
+
- **confidential clients** are clients which can authenticate themselves to Authorization Servers using a cryptographic signing key. This allows refresh tokens to be bound to the specific client. Note that this form of client authentication is distinct from DPoP: the client authentication key is common to all client sessions (although it can be rotated). This usually means that there is a web service controlled by the client which holds the key. Because they are authenticated and can revoke tokens in a security incident, confidential clients may be trusted with longer session and token lifetimes.
55
+
- **public clients** do not authenticate using a client signing key, either because they don’t have a server-side component (the client software all runs on end-user devices), or they simply chose not to implement it.
56
+
57
+
It is acceptable for a web service to act as a public client, and conversely it is possible for mobile apps and browser apps to coordinate with a token-mediating backend service and for the combination to form a confidential client. Mobile apps and browser apps can also adopt a "backend-for-frontend" (BFF) architecture with a web service backend acting as the OAuth client. This document will use the "public" vs "confidential" client terminology for clarity.
58
+
59
+
The environment a client runs in also impacts the type of redirect (callback) URLs it uses during the Authorization Flow:
60
+
61
+
- **web clients** include web services and browser apps. Redirect URLs are regular web URLs which open in a browser.
62
+
- **native clients** include some mobile and desktop native clients. Redirect URLs may use platform-specific app callback schemes to open in the app itself.
63
+
64
+
Authorization Servers may maintain a set of "trusted" clients, identified by `client_id`. Because any client could use unverified client metadata to impersonate a better-known app or brand, Authorization Servers should not display such metadata to end users in the Authorization Interface by default. Trusted clients can have additional metadata shown, such as a readable name (`client_name`), project URI (`client_uri`, which may have a different domain/origin than `client_id`) and logo (`logo_uri`). See the "Security Considerations" section for more details.
65
+
66
+
Clients which are only using atproto OAuth for account authentication (without authorization to access PDS resources) should request minimal scopes (see "Scopes" section), but still need to implement most of the authorization flow. In particular, it is critical that they check the `sub` field in a token response to verify the account identity (this is an atproto-specific detail).
67
+
68
+
### Client ID Metadata Document
69
+
70
+
The Client ID Metadata Document specification ([`draft-parecki-oauth-client-id-metadata-document`](https://datatracker.ietf.org/doc/draft-parecki-oauth-client-id-metadata-document/) is still a draft and may evolve over time. Our intention is to evolve and align with subsequent drafts and any final standard, while minimizing disruption and breakage with existing implementations.
71
+
72
+
Clients must publish a "client metadata" JSON file on the public web. This will be fetched dynamically by Authorization Servers as part of the authorization request (PAR) and at other times during the session lifecycle. The response HTTP status must be 200 (not another 2xx or a redirect), with a JSON object body with the correct `Content-Type` (`application/json`).
73
+
74
+
Authorization Servers need to fetch client metadata documents from the public web. They should use a hardened HTTP client for these requests (see "OAuth Security Considerations"). Servers may cache client metadata responses, optionally respecting HTTP caching headers (within limits). Minimum and maximum cache TTLs are not currently specified, but should be chosen to ensure that auth token requests predicated on stale confidential client authentication keys (`jwks` or `jwks_uris`) are rejected in a timely manner.
75
+
76
+
The following fields are relevant for all client types:
77
+
78
+
- `client_id` (string, required): the `client_id`. Must exactly match the full URL used to fetch the client metadata file itself
79
+
- `application_type` (string, optional): must be one of `web` or `native`, with `web` as the default if not specified. Note that this is field specified by OpenID/OIDC, which we are borrowing. Used by the Authorization Server to enforce the relevant "best current practices".
80
+
- `grant_types` (array of strings, required): `authorization_code` must always be included. `refresh_token` is optional, but must be included if the client will make token refresh requests.
81
+
- `scope` (string, sub-strings space-separated, required): all scope values which *might* be requested by this client are declared here. The `atproto` scope is required, so must be included here. See "Scopes" section.
82
+
- `response_types` (array of strings, required): `code` must be included.
83
+
- `redirect_uris` (array of strings, required): at least one redirect URI is required. See Authorization Request Fields section for rules about redirect URIs, which also apply here.
84
+
- `token_endpoint_auth_method` (string, optional): confidential clients must set this to `private_key_jwt`.
85
+
- `token_endpoint_auth_signing_alg` (string, optional): `none` is never allowed here. The current recommended and most-supported algorithm is `ES256`, but this may evolve over time. Authorization Servers will compare this against their supported algorithms.
86
+
- `dpop_bound_access_tokens` (boolean, required): DPoP is mandatory for all clients, so this must be present and `true`
87
+
- `jwks` (object with array of JWKs, optional): confidential clients must supply at least one public key in JWK format for use with JWT client authentication. Either this field or the `jwks_uri` field must be provided for confidential clients, but not both.
88
+
- `jwks_uri` (string, optional): URL pointing to a JWKS JSON object. See `jwks` above for details.
89
+
90
+
These fields are optional but recommended:
91
+
92
+
- `client_name` (string, optional): human-readable name of the client
93
+
- `client_uri` (string, optional): not to be confused with `client_id`, this is a homepage URL for the client. If provided, the `client_uri` must have the same hostname as `client_id`.
94
+
- `logo_uri` (string, optional): URL to client logo. Only `https:` URIs are allowed.
95
+
- `tos_uri` (string, optional): URL to human-readable terms of service (ToS) for the client. Only `https:` URIs are allowed.
96
+
- `policy_uri` (string, optional): URL to human-readable privacy policy for the client. Only `https:` URIs are allowed.
97
+
98
+
See "OAuth Security Considerations" below for when `client_name`, `client_uri`, and `logo_uri` will or will not be displayed to end users.
99
+
100
+
Additional optional client metadata fields are enumerated with [IANA](https://www.iana.org/assignments/oauth-parameters/oauth-parameters.xhtml#client-metadata). Note that these are shared with the "Dynamic Client Registration" standard, which is not used directly by the atproto OAuth profile.
101
+
102
+
### Localhost Client Development
103
+
104
+
When working with a developent environment (Authorization Server and Client), it may be difficult for developers to publish in-progress client metadata at a public URL so that authorization servers can access it. This may even be true for development environments using a containerized Authorization Server and local DNS, because of SSRF protections against local IP ranges.
105
+
106
+
To make development workflows easier, a special exception is made for clients with `client_id` having origin `http://localhost` (with no port number specified). Authorization Servers are encouraged to support this exception - including in production environments - but it is optional.
107
+
108
+
In a localhost `client_id` scenario, the Authorization Server should verify that the scheme is `http`, and that the hostname is exactly `localhost` with no port specified. IP addresses (`127.0.0.1`, etc) are not supported. The path parameter must be empty (`/`).
109
+
110
+
In the Authorization Request, the `redirect_uri` must match one of those supplied (or a default). Path components must match, but port numbers are not matched.
111
+
112
+
Some metadata fields can be configured via query parameter in the `client_id` URL (with appropriate urlencoding):
113
+
114
+
- `redirect_uri` (string, multiple query parameters allowed, optional): allows declaring a local redirect/callback URL, with path component matched but port numbers ignored. The default values (if none are supplied) are `http://127.0.0.1/` and `http://[::1]/`.
115
+
- `scope` (string with space-separated values, single query parameter allowed, optional): the set of scopes which might be requested by the client. Default is `atproto`.
116
+
117
+
The other parameters in the virtual client metadata document will be:
118
+
119
+
- `client_id` (string): the exact `client_id` (URL) used to generate the virtual document
120
+
- `client_name` (string): a value chosen by the Authorization Server (e.g. "Development client")
121
+
- `response_types` (array of strings): must include `code`
122
+
- `grant_types` (array of strings): `authorization_code` and `refresh_token`
123
+
- `token_endpoint_auth_method`: `none`
124
+
- `application_type`: `native`
125
+
- `dpop_bound_access_tokens`: `true`
126
+
127
+
Note that this works as a public client, not a confidential client.
128
+
129
+
As mentioned in the introduction, OAuth 2.0 generally provides only Authorization (`authz`), and additional standards like OpenID/OIDC are used for Authentication (`authn`). The atproto profile of OAuth requires authentication of account identity and supports the use case of simple identity authentication without additional resource access authorization.
130
+
131
+
In atproto, account identity is anchored in the account DID, which is the permanent, globally unique, publicly resolvable identifier for the account. The DID resolves to a DID document which indicates the current PDS host location for the account. That PDS (combined with an optional entryway) is the authorization authority and the OAuth Authorization Server for the account. When speaking to any Authorization Server, it is critical (mandatory) for clients to confirm that it is actually the authoritative server for the account in question, which means independently resolving the account identity (by DID) and confirming that the Authorization Server matches. It is also critical (mandatory) to confirm at the end of an authorization flow that the Authorization Server actually authorized the expected account. The reason this is necessary is to confirm that the Authorization Server is authoritative for the account in question. Otherwise a malicious server could authenticate arbitrary accounts (DIDs) to the client.
132
+
133
+
Clients can start an auth flow in one of two ways:
134
+
135
+
- starting with a public account identifier, provided by the user: handle or DID
136
+
- starting with a server hostname, provided by the user: PDS or entryway, mapping to either Resource Server and/or Authorization Server
137
+
138
+
One use case for starting with a server instead of an account identifier is when the user does not remember their full account handle or only knows their account email. Another is for authentication when a user’s handle is broken. The user will still need to know their hosting provider in these situation.
139
+
140
+
When starting with an account identifier, the client must resolve the atproto identity to a DID document. If starting with a handle, it is critical (mandatory) to bidirectionally verify the handle by checking that the DID document claims the handle (see atproto Handle specification). All handle resolution techniques and all atproto-blessed DID methods must be supported to ensure interoperability with all accounts.
141
+
142
+
In some client environments, it may be difficult to resolve all identity types. For example, handle resolution may involve DNS TXT queries, which are not directly supported from browser apps. Client implementations might use alternative techniques (such as DNS-over-HTTP) or could make use of a supporting web service to resolve identities.
143
+
144
+
Because authorization flows are security-critical, any caching of identity resolution should choose cache lifetimes carefully. Cache lifetimes of less than 10 minutes are recommended for auth flows specifically.
145
+
146
+
The resolved DID should be bound to the overall auth session and should be used as the primary account identifier within client app code. Handles (when verified) are acceptable to display in user interfaces, but may change over time and need to be re-verified periodically. When passing an account identifier through to the Authorization Server as part of the Authorization Request in the `login_hint`, it is recommended to use the exact account identifier supplied by the user (handle or DID) to ensure any sign-in flow is consistent (users might not recognize their own account DID).
147
+
148
+
At the end of the auth flow, when the client does an initial token fetch, the Authorization Server must return the account DID in the `sub` field of the JSON response body. If the entire auth flow started with an account identifier, it is critical for the client to verify that this DID matches the expected DID bound to the session earlier; the linkage from account to Authorization Server will already have been verified in this situation.
149
+
150
+
If the auth flow instead starts with a server (hostname or URL), the client will first attempt to fetch Resource Server metadata (and resolve to Authorization Server if found) and then attempt to fetch Authorization Server metadata. See "Authorization Server" section for server metadata fetching. If either is successful, the client will end up with an identified Authorization Server. The Authorization Request flow will proceed without a `login_hint` or account identifier being bound to the session, but the Authorization Server `issuer` will be bound to the session.
151
+
152
+
After the auth flow continues and an initial token request succeeds, the client will parse the account identifier from the `sub` field in the token response. At this point, the client still cannot trust that it has actually authenticated the indicated account. It is critical for the client to resolve the identity (DID document), extract the declared PDS host, confirm that the PDS (Resource Server) resolves to the Authorization Server bound to the session by fetching the Resource Server metadata, and fetch the Authorization Server metadata to confirm that the `issuer` field matches the Authorization Server origin (see [`draft-ietf-oauth-v2-1` section 7.3.1](https://datatracker.ietf.org/doc/html/draft-ietf-oauth-v2-1-11#section-7.13.1) regarding this last point).
153
+
154
+
To reiterate, it is critical for all clients - including those only interested in atproto Identity Authentication - to go through the entire Authorization flow and to verify that the account identifier (DID) in the `sub` field of the token response is consistent with the Authorization Server hostname/origin (`issuer`).
155
+
156
+
OAuth scopes allow more granular control over the resources and actions a client is granted access to.
157
+
158
+
The special `atproto` scope is required for all atproto OAuth sessions. The semantics are somewhat similar to the `openid` scope: inclusion of it confirms that the client is using the atproto profile of OAuth and will comply with all the requirements laid out in this specification. No access to any atproto-specific PDS resources will be granted without this scope included.
159
+
160
+
Authorization Servers may support other profiles of OAuth if client does not include the `atproto` scope. For example, an Authorization Server might function as both an atproto PDS/entryway, and support other protocols/standards at the same time.
161
+
162
+
Use of the atproto OAuth profile, as indicated by the `atproto` scope, means that the Authorization Server will return the atproto account DID as an account identifier in the `sub` field of token requests. Authorization Servers must return `atproto` in `scopes_supported` in their metadata document, so that clients know they support the atproto OAuth profile. A client may include only the `atproto` scope if they only need account authentication - for example a "Login with atproto" use case. Unlike OpenID, profile metadata in atproto is generally public, so an additional authorization scope for fetching profile metadata is not needed.
163
+
164
+
The OAuth 2.0 specification does not require Authorization Servers to return the granted scopes in the token responses unless the scope that was granted is different from what the client requested. In the atproto OAuth profile, servers must always return the granted scopes in the token response. Clients should reject token responses if they don't contain a `scope` field, or if the `scope` field does not contain `atproto`.
165
+
166
+
The intention is to support flexible scopes based on Lexicon namespaces (NSIDs) so that clients can be given access only to the specific content and API endpoints they need access to. Until the design of that scope system is ready, the atproto profile of OAuth defines two transitional scopes which align with the permissions granted under the original "session token" auth system:
167
+
168
+
- `transition:generic`: broad PDS account permissions, equivalent to the previous "App Password" authorization level.
169
+
- write (create/update/delete) any repository record type
170
+
- upload blobs (media files)
171
+
- read and write any personal preferences
172
+
- API endpoints and service proxying for most Lexicon endpoints, to any service provider (identified by DID)
173
+
- ability to generate service auth tokens for the specific API endpoints the client has access to
174
+
- no account management actions: change handle, change email, delete or deactivate account, migrate account
175
+
- no access to DMs (the `chat.bsky.*` Lexicons), specifically
176
+
- `transition:chat.bsky`: equivalent to adding the "DM Access" toggle for "App Passwords"
177
+
- API endpoints and service proxying for the `chat.bsky` Lexicons specifically
178
+
- ability to generate service auth tokens for the `chat.bsky` Lexicons
179
+
- this scope depends on and does not function without the `transition:generic` scope
180
+
181
+
This section details standards and requirements specific to Authorization Requests.
182
+
183
+
PKCE and PAR are required for all client types and Authorization Servers. Confidential clients authenticate themselves using JWT client assertions.
184
+
185
+
### Request Fields
186
+
187
+
A summary of fields relevant to authorization requests with the atproto OAuth profile:
188
+
189
+
- `client_id` (string, required): identifies the client software. See "Clients" section above for details.
190
+
- `response_type` (string, required): must be `code`
191
+
- `code_challenge` (string, required): the PKCE challenge value. See "PKCE" section.
192
+
- `code_challenge_method` (string, required): which code challenge method is used, for example `S256`. See "PKCE" section.
193
+
- `state` (string, required): random token used to verify the authorization request against the response. See below.
194
+
- `redirect_uri` (string, required): must match against URIs declared in client metadata and have a format consistent with the `application_type` declared in the client metadata. See below.
195
+
- `scope` (string with space-separated values, required): must be a subset of the scopes declared in client metadata. Must include `atproto`. See "Scopes" section.
196
+
- `client_assertion_type` (string, optional): used by confidential clients to describe the client authentication mechanism. See "Confidential Client" section.
197
+
- `client_assertion` (string, optional): only used for confidential clients, for client authentication. See "Confidential Client" section.
198
+
- `login_hint` (string, optional): account identifier to be used for login. See "Authorization Interface" section.
199
+
200
+
The `client_secret` value, used in many other OAuth profiles, should not be included.
201
+
202
+
The `state` parameter in client authorization requests is mandatory. Clients should use randomly-generated tokens for this parameter and not have collisions or reuse tokens across any combination of device, account, or session. Authorization Servers should reject duplicate state parameters, but are not currently required to track state values across accounts or sessions. The `state` parameter is effectively used to verify the `issuer` later, and it is important that the parameter can not be forged or guessed by an untrusted party.
203
+
204
+
For web clients, the `redirect_uri` is a HTTPS URL which will be redirected in the browser to return users to the application at the end of the Authorization flow. The URL may include a port number, but not if it is the default port number. The `redirect_uri` must match one of the URIs declared in the client metadata and the Authorization Server must verify this condition. The URL origin must match that of the `client_id`.
205
+
206
+
There is a special exception for the localhost development workflow to use `http://127.0.0.1` or `http://[::1]` URLs, with matching rules described in the "Localhost Client Development" section. These clients use web URLs, but have `application_type` set to `native` in the generated client metadata.
207
+
208
+
For native clients, the `redirect_uri` may use a custom URI scheme to have the operating system redirect the user back to the app, instead of a web browser. Native clients are also allowed to use an HTTPS URL. Any custom scheme must match the `client_id` hostname in reverse-domain order. The URI scheme must be followed by a single colon (`:`) then a single forward slash (`/`) and then a URI path component. For example, an app with `client_id` [`https://app.example.com/client-metadata.json`](https://app.example.com/client-metadata.json) could have a `redirect_uri` of `com.example.app:/callback`.
209
+
210
+
Native clients are also allowed to use an HTTPS URL. In this case, the URL origin must be the same as the `client_id`. One example use-case is "Apple Universal Links".
211
+
212
+
Clients may include additional optional authorization request parameters - and servers may process them - but they are not required to. Refer to other OAuth standards and the [IANA OAuth parameter registry](https://www.iana.org/assignments/oauth-parameters/oauth-parameters.xhtml).
213
+
214
+
### Proof Key for Code Exchange (PKCE)
215
+
216
+
PKCE is mandatory for all Authorization Requests. Clients must generate new, unique, random challenges for every authorization request. Authorization Servers must prevent reuse of `code_challenge` values across sessions (at least within some reasonable time frame, such as a 24 hour period).
217
+
218
+
The `S256` challenge method must be supported by all clients and Authorization Servers; see [RFC 7636](https://datatracker.ietf.org/doc/html/rfc7636) for details. The `plain` method is not allowed. Additional methods may in theory be supported if both client and server support them.
219
+
220
+
Authorization Servers should reject reuse of a `code` value, and revoke any outstanding sessions and tokens associated with the earlier use of the `code` value.
221
+
222
+
### Pushed Authorization Requests (PAR)
223
+
224
+
Authorization Servers must support PAR and clients of all types must use PAR for Authorization Requests.
225
+
226
+
Authorization Servers must set `require_pushed_authorization_requests` to `true` in their server metadata document and include a valid URL in `pushed_authorization_request_endpoint`. See [RFC 9207](https://datatracker.ietf.org/doc/html/rfc9207) for requirements on this URL.
227
+
228
+
Clients make an HTTPS POST request to the `pushed_authorization_request_endpoint` URL, with the request parameters in the form-encoded request body. They receive a `request_uri` (not to be confused with `redirect_uri`) in the JSON response object. When they redirect the user to the authorization endpoint (`authorization_endpoint`), they omit most of the request parameters they already sent and include this `redirect_uri` along with `client_id` as query parameters instead.
229
+
230
+
PAR is a relatively new and less-supported standard, and the requirement to use PAR may be relaxed if it is found to be too onerous a requirement for client implementations. In that case, Authorization Servers would be required to support both PAR and non-PAR requests with PAR being optional for clients.
231
+
232
+
### Confidential Client Authentication
233
+
234
+
Confidential clients authenticate themselves during the Authorization Request using a JWT client assertion. Authorization Servers may grant confidential clients longer token/session lifetimes. See "Tokens" section for more context.
235
+
236
+
The client assertion type to use is `urn:ietf:params:oauth:client-assertion-type:jwt-bearer`, as described in "JSON Web Token (JWT) Profile for OAuth 2.0 Client Authentication and Authorization Grants" ([RFC 7523](https://datatracker.ietf.org/doc/html/rfc7523)). Clients and Authorization Servers currently must support the `ES256` cryptographic system. The set of recommended systems/algorithms is expected to evolve over time.
237
+
238
+
Additional requirements:
239
+
240
+
- confidential clients must publish one or more client authentication keys (public key) in the client metadata. This can be either direct JWK format as JSON in the `jwks` field, or as a separate JWKS JSON object on the web linked by a `jwks_uri` URL. A `jwks_uri` URL must be a valid fully qualified URL with `https://` scheme.
241
+
- confidential clients should periodically rotate client keys, adding new keys to the JWKS set and using then for new sessions, then removing old keys once they are no longer associated with any active auth sessions
242
+
- confidential clients must include `token_endpoint_auth_method` as `private_key_jwt` in their client metadata document
243
+
- confidential clients are expected to immediately remove client authentication keys from their client metadata if the key has been leaked or compromised
244
+
- Authorization Servers must bind active auth sessions for confidential clients to the client authentication key used at the start of the session. The server should revoke the session and reject further token refreshes if the client authentication key becomes absent from the client metadata. This means the Authorization Server is expected to periodically re-fetch client metadata.
245
+
246
+
Access tokens are used to authorize client requests to the account's PDS ("Resource Server"). From the standpoint of the client they are opaque, but they are often signed JWTs including an expiration time. Depending on the PDS implementation, it may or may not be possible to revoke individual access tokens in the event of a compromise, so they must be restricted to a relatively short lifetime.
247
+
248
+
Refresh tokens are used to request new tokens (of both types) from the Authorization Server (PDS or entryway). They are also opaque from the standpoint of clients. Auth sessions can be revoked - invalidating the refresh tokens - so they may have a longer lifetime. In the atproto OAuth profile, refresh tokens are generally single-use, with the "new" refresh token replacing that used in the token request. This means client implementations may need locking primitives to prevent concurrent token refresh requests.
249
+
250
+
To request refresh tokens, the client must declare `refresh_token` as a grant type in their client metadata.
251
+
252
+
Tokens are always bound to a unique session DPoP key. Tokens must not be shared or reused across client devices. They must also be uniquely bound to the client software (`client_id`). The overall session ends when the access and refresh tokens can no longer be used.
253
+
254
+
The specific lifetime of sessions, access tokens, and refresh tokens is up to the Authorization Server implementation and may depend on security assessments of client type and reputation.
255
+
256
+
Some guidelines and requirements:
257
+
258
+
- access token lifetimes should be less than 30 minutes in all situations. If the server cannot revoke individual access tokens then the maximum is 15 minutes, and 5 minutes is recommended.
259
+
- for "untrusted" public clients, overall session lifetime should be limited to 7 days, and the lifetime of individual refresh tokens should be limited to 24 hours
260
+
- for confidential clients, the overall session lifetime may be unlimited. Individual refresh tokens should have a lifetime limited to 180 days
261
+
- confidential clients must use the same client authentication key and assertion method for refresh token requests that they did for the initial authentication request
262
+
263
+
The atproto OAuth profile mandates use of DPoP for all client types when making auth token requests to the Authorization Server and when making authorized requests to the Resource Server. See [RFC 9449](https://datatracker.ietf.org/doc/html/rfc9449) for details.
264
+
265
+
Clients must initiate DPoP in the initial authorization request (PAR).
266
+
267
+
Server-provided DPoP nonces are mandatory. The Resource Server and Authorization Server may share nonces (especially if they are the same server) or they may have separate nonces. Clients should track the DPoP nonce per account session and per server. Servers must rotate nonces periodically, with a maximum lifetime of 5 minutes. Servers may use the same nonce across all client sessions and across multiple requests at any point in time. Servers should accept recently-stale (old) nonces to make rotation smoother for clients with multiple concurrent request in-flight. Clients should be resilient to unexpected nonce updates in the form of HTTP 400 errors and should retry those failed requests. Clients must reject responses missing a `DPoP-Nonce` header (case insensitive), if the request included DPoP.
268
+
269
+
Clients must generate and sign a unique DPoP token (JWT) for every request. Each DPoP request JWT must have a unique (randomly generated) `jti` nonce. Servers should prevent token replays by tracking `jti` nonces and rejecting re-use. They can restrict their client-generated `jti` nonce history to the server-generated DPoP nonce so that they do not need to track an endlessly growing set of nonces.
270
+
271
+
The `ES256` (NIST "P-256") cryptographic algorithm must be supported by all clients and servers for DPoP JWT signing. The set of algorithms recommended for use is expected to evolve over time. Clients and Servers may implement additional algorithms and declare them in metadata documents to facilitate cryptographic evolution and negotiation.
272
+
273
+
To enable browser apps, Authorization Servers must support HTTP CORS requests/headers on relevant endpoints, including server metadata, auth requests (PAR), and token requests.
274
+
275
+
### Server Metadata
276
+
277
+
Both Resource Servers (PDS instances) and Authorization Servers (PDS or entryway) need to publish metadata files at well-known HTTPS endpoints.
278
+
279
+
Resource Server (PDS) metadata must comply with the "OAuth 2.0 Protected Resource Metadata" ([`draft-ietf-oauth-resource-metadata`](https://datatracker.ietf.org/doc/draft-ietf-oauth-resource-metadata/)) draft specification. A summary of requirements:
280
+
281
+
- the URL path is `/.well-known/oauth-protected-resource`
282
+
- response must be an HTTP 200 (not 2xx or redirect), and must be a valid JSON object with content type `application/json`
283
+
- must contain an `authorization_servers` array of strings, with a single element, which is a fully-qualified URL
284
+
285
+
The Authorization Server URL may be the same origin as the Resource Server (PDS), or might point to a separate server (e.g. entryway). The URL must be a simple origin URL: `https` scheme, no credentials (user:password), no path, no query string or fragment. A port number is allowed, but a default port (443 for HTTPS) must not be included.
286
+
287
+
The Authorization Server also publishes metadata, complying with the "OAuth 2.0 Authorization Server Metadata" ([RFC 8414](https://datatracker.ietf.org/doc/html/rfc8414)) standard. A summary of requirements:
288
+
289
+
- the URL path is `/.well-known/oauth-authorization-server`
290
+
- response must be an HTTP 200 (not 2xx or redirect), and must be a valid JSON object with content type `application/json`
291
+
- `issuer` (string, required): the "origin" URL of the Authorization Server. Must be a valid URL, with `https` scheme. A port number is allowed (if that matches the origin), but the default port (443 for HTTPS) must not be specified. There must be no path segments. Must match the origin of the URL used to fetch the metadata document itself.
292
+
- `authorization_endpoint` (string, required): endpoint URL for authorization redirects
293
+
- `token_endpoint` (string, required): endpoint URL for token requests
294
+
- `response_types_supported` (array of strings, required): must include `code`
295
+
- `grant_types_supported` (array of strings, required): must include `authorization_code` and `refresh_token` (refresh tokens must be supported)
296
+
- `code_challenge_methods_supported` (array of strings, required): must include `S256` (see "PKCE" section)
297
+
- `token_endpoint_auth_methods_supported` (array of strings, required): must include both `none` (public clients) and `private_key_jwt` (confidential clients)
298
+
- `token_endpoint_auth_signing_alg_values_supported` (array of strings, required): must not include `none`. Must include `ES256` for now. Cryptographic algorithm suites are expected to evolve over time.
299
+
- `scopes_supported` (array of strings, required): must include `atproto`. If supporting the transitional grants, they should be included here as well. See "Scopes" section.
300
+
- `authorization_response_iss_parameter_supported` (boolean): must be `true`
301
+
- `require_pushed_authorization_requests` (boolean): must be `true`. See "PAR" section.
302
+
- `pushed_authorization_request_endpoint` (string, required): must be the PAR endpoint URL. See "PAR" section.
303
+
- `dpop_signing_alg_values_supported` (array of strings, required): currently must include `ES256`. See "DPoP" section.
304
+
- `require_request_uri_registration` (boolean, optional): default is `true`; does not need to be set explicitly, but must not be `false`
305
+
- `client_id_metadata_document_supported` (boolean, required): must be `true`. See "Client ID Metadata" section.
306
+
307
+
The `issuer` ("origin") is the overall identifier for the Authorization Server.
308
+
309
+
### Authorization Interface
310
+
311
+
The Authorization Server (PDS/entryway) must implement a web interface for users to authenticate with the server, approve (or reject) Authorization Requests from clients, and manage active sessions. This is called the "Authorization Interface".
312
+
313
+
Server implementations can chose their own technology for user authentication and account recovery: secure cookies, email, various two-factor authentication, passkeys, external identity providers (including upstream OpenID/OIDC), etc. Servers may also support multiple concurrent auth sessions with users.
314
+
315
+
When a client redirects to the Authorization Server’s authorization URL (the declared `authorization_endpoint`), the server first needs to authenticate the user. If there is no active auth session, the user may be prompted to log in. If a `login_hint` was provided in the Authorization Request, that can be used to pre-populate the login form. If there are multiple active auth sessions, the user could be prompted to select one from a list, or the `login_hint` could be used to auto-select. If there is a single active session, the interface can move to the approval view, possibly with the option to login as a different account. If a `login_hint` was supplied, the Authorization Server should only allow the user to authenticate with that account. Otherwise the overall authorization flow will fail when the client verifies the account identity (`sub` field).
316
+
317
+
The authorization approval prompt should identify the client app and describe the scope of authorization that has been requested.
318
+
319
+
The amount of client metadata that should be displayed may depend on whether the client is "trusted" by the Authorization Server; see the "Client" and "Security Concerns" sections. The full `client_id` URL should be displayed by default.
320
+
321
+
See the "Scopes" section for a description of scope options.
322
+
323
+
If a client is a confidential client and the user has already approved the same scopes for the same client in the past, the Authorization Server may allow "silent sign-in" by auto-approving the request. Authorization Servers can set their own policies for this flow: it may require explicit user configuration, or the client may be required to be "trusted".
324
+
325
+
Authorization Servers should separately implement a web interface which allows authenticated users to view active OAuth sessions and delete them.
326
+
327
+
This is a high-level description of what an atproto OAuth authorization flow looks like. It assumes the user already has an atproto account.
328
+
329
+
The client starts by asking for the user’s account identifier (handle or DID), or for a PDS/entryway hostname. See "Identity Authentication" section for details.
330
+
331
+
For an account identifier, the client resolves the identity to a DID document, extracts the declared PDS URL, then fetches the Resource Server and Authorization Server locations. If starting with a server hostname, the client resolves that hostname to an Authorization Server. In either case, Authorization Server metadata is fetched and verified against requirements for atproto OAuth (see "Authorization Server" section).
332
+
333
+
The client next makes a Pushed Authorization Request via HTTP POST request. See "Authorization Request" section; some notable details include:
334
+
335
+
- a randomly generated `state` token is required, and will be used to reference this authorization request with the subsequent response callback
336
+
- PKCE is required, so a secret value is generated and stored, and a derived challenge is included in the request
337
+
- `scope` values are requested here, and must include `atproto`
338
+
- for confidential clients, a `client_assertion` is included, with type `jwt-bearer`, signed using the secret client authentication key
339
+
- the client generates a new DPoP key for the user/device/session and uses it starting with the PAR request
340
+
- if the auth flow started with an account identifier, the client should pass that starting identifier via the `login_hint` field
341
+
- atproto uses PAR, so the request will be sent as an HTTP POST request to the Authorization Server
342
+
343
+
The Authorization Server will receive the PAR request and use the `client_id` URL to resolve the client metadata document. The server validates the request and client metadata, then stores information about the session, including binding a DPoP key to the session. The server returns a `request_uri` token to the client, including a DPoP nonce via HTTP header.
344
+
345
+
The client receives the `request_uri` and prepares to redirect the user. At this point, the client usually needs to persist information about the session to some type of secure storage, so it can be read back after the redirect returns. This might be a database (for a web service backend) or web platform storage like IndexedDB (for a browser app). The client then redirects the user via browser to the Authorization Server’s auth endpoint, including the `request_uri` as a URL parameter. In any case, clients must not store session data directly in the `state` request param.
346
+
347
+
The Authorization Server uses the `request_uri` to look up the earlier Authorization Request parameters, authenticates the user (which might include sign-in or account selection), and prompts the user with the Authorization Interface. The user might refine any granular requested scopes, then approves or rejects the request. The Authorization Server redirects the user back to the `redirect_uri`, which might be a web callback URL, or a native app URI (for native clients).
348
+
349
+
The client uses URL query parameters (`state` and `iss`) to look up and verify session information. Using the `code` query parameter, the client then makes an initial token request to the Authorization Server’s token endpoint. The client completes the PKCE flow by including the earlier value in the `code_verifier` field. Confidential clients need to include a client assertion JWT in the token request; see the "Confidential Client" section. The Authorization Server validates the request and returns a set of tokens, as well as a `sub` field indicating the account identifier (DID) for this session, and the `scope` that is covered by the issued access token.
350
+
351
+
At this point it is critical (mandatory) for all clients to verify that the account identified by the `sub` field is consistent with the Authorization Server "issuer" (present in the `iss` query string), either by validating against the originally-supplied account DID, or by resolving the accounts DID to confirm the PDS is consistent with the Authorization Server. See "Identity Authentication" section. The Authorization always returns the scopes approved for the session in the `scopes` field (even if they are the same as the request, as an atproto OAuth profile requirement), which may reflect partial authorization by the user. Clients must reject the session if the response does not include `atproto` in the returned scopes.
352
+
353
+
Authentication-only clients can end the flow here.
354
+
355
+
Using the access token, clients are now able to make authorized requests to the PDS ("Resource Server"). They must use DPoP for all such requests, along with the access token. Tokens (both access and refresh) will need to be periodically "refreshed" by subsequent request to the Authorization Server token endpoint. These also require DPoP. See "Tokens and Session Lifetime" section for details.
356
+
357
+
There are a number of situations where HTTP URLs provided by external parties are fetched by both clients and providers (servers). Care must be taken to prevent harmful fetches due to maliciously crafted URLs, including hostnames which resolve to private or internal IP addresses. The general term for this class of security issue is Server-Side Request Forgery (SSRF). There is also a class of denial-of-service attacks involving HTTP requests to malicious servers, such as huge response bodies, TCP-level slow-loris attacks, etc. We strongly recommend using "hardened" HTTP client implementations/configurations to mitigate these attacks.
358
+
359
+
Any party can create a client and client metadata file with any contents at any time. Even the hostname in the `client_id` cannot be entirely trusted to represent the overall client: an untrusted user may have been able to upload the client metadata file to an arbitrary URL on the host. In particular, the `client_uri`, `client_name`, and `logo_uri` fields are not verified and could be used by a malicious actor to impersonate a legitimate client. It is strongly recommended for Authorization Servers to not display these fields to end users during the auth flow for unknown clients. Service operators may maintain a list of "trusted" `client_id` values and display the extra metadata for those apps only.
360
+
361
+
Client metadata requests (by the authorization server) might fail for any number of reasons: transient network disruptions, the client server being down for regular maintenance, etc. It seems brittle for the Authorization Server to immediately revoke access to active client sessions in this scenario. Maybe there should be an explicit grace period?
362
+
363
+
The requirement that resource server metadata only have a single URL reference to an authorization server might be relaxed.
364
+
365
+
The details around session and token lifetimes might change with further security review.
+292
contextual info for claude/OAuth Client Implementation Bluesky.md
+292
contextual info for claude/OAuth Client Implementation Bluesky.md
···
1
+
---
2
+
title: "OAuth Client Implementation | Bluesky"
3
+
source: "https://docs.bsky.app/docs/advanced-guides/oauth-client"
4
+
author:
5
+
published:
6
+
created: 2025-03-07
7
+
description: "This is a guide to implementing atproto OAuth clients \"The Hard Way.\" Optimistically, most developers will have an SDK available for their programming language which supports OAuth, and they can simply refer to SDK documentation. This guide is intended for early adopters, SDK maintainers, or developers with more sophisticated OAuth needs. It is agnostic to whether developers are building clients to work the the app.bsky microblogging Lexicons, or implementing novel application Lexicons."
8
+
tags:
9
+
- "clippings"
10
+
---
11
+
This is a guide to implementing atproto OAuth clients "The Hard Way." Optimistically, most developers will have an SDK available for their programming language which supports OAuth, and they can simply refer to SDK documentation. This guide is intended for early adopters, SDK maintainers, or developers with more sophisticated OAuth needs. It is agnostic to whether developers are building clients to work the the `app.bsky` microblogging Lexicons, or implementing novel application Lexicons.
12
+
13
+
The [atproto OAuth specification](https://atproto.com/specs/auth) is the authoritative document on how to use OAuth with atproto. If there are discrepancies between this document and the specification, defer to the specification. This document skips over a few details and uses more atproto-specific terminology, but readers are still expected to be familiar with OAuth 2 concepts, terminology, and standards.
14
+
15
+
This guide is focused on apps which use OAuth to make authorized ("authz") requests to user PDS servers, for example to write records to atproto repositories, or make proxied API requests to other services. It is also possible to use the atproto identity system only for authentication ("authn"), similar to OpenID/OIDC.
16
+
17
+
## Types of Clients
18
+
19
+
This guide covers three simplified types of OAuth client:
20
+
21
+
- **Web Services**: traditional web apps which involve a server/backend running code to make actual PDS requests and talk with a database. There is some form of auth between browsers and the web service, such as cookie sessions; this auth layer is distinct from OAuth. The server may return complete HTML pages, or there may be an API between code running in the browser and code running on the server. Integrations with and extensions of existing web services also fall under this category.
22
+
- **Browser Apps**: "single-page" applications which run in a web browser, implemented using web platform APIs and JavaScript or WASM runtimes. The server-side ("backend") component is minimal, or even just static file hosting.
23
+
- **Mobile and Desktop Apps**: what they sound like: "native" apps that run on mobile operating systems (smartphones, tablets, etc), or desktop applications
24
+
25
+
| | **Web Service** | **Browser App** | **Mobile or Desktop App** |
26
+
| --- | --- | --- | --- |
27
+
| **OAuth 2 Client Type** | "Confidential" | "Public" | "Public" |
28
+
| `client_id` | ✅ URL to metadata | ✅ URL to metadata | ✅ URL to metadata |
29
+
| `client_secret` | ❌ | ❌ | ❌ |
30
+
| **OAuth 2 Grant Types** | `authorization_code`, `refresh_token` | `authorization_code`, `refresh_token` | `authorization_code`, `refresh_token` |
31
+
| **Client Metadata** | ✅ Public Web | ✅ Public Web | ✅ Public Web |
32
+
| **Client Metadata JWK** | ✅ Public Web | ❌ | ❌ |
33
+
| **PKCE** | ✅ | ✅ | ✅ |
34
+
| **PAR** | ✅ | ✅ | ✅ |
35
+
| **DPoP** | ✅ | ✅ | ✅ |
36
+
| **Handle Resolution** | DNS and HTTPS | DNS-over-HTTPS and HTTPS or via helper service | DNS and HTTPS or via helper service |
37
+
| **DID Resolution** | HTTPS | HTTPS | HTTPS |
38
+
| **Recommended Client Secret Key Storage** | Environment Variable, Secrets Manager, Hardware Enclave | ❌ | ❌ |
39
+
| **Recommended DPoP Key Storage** | Secure Database | non-exportable CryptoKeyPair in IndexedDB | Secure File or Database, Hardware Enclave |
40
+
| **Recommended Token Storage** | Secure Database | IndexedDB or LocalStorage | Secure File or Database |
41
+
| **SSRF + DoS Hardening** | ✅ | ✅ | ✅ |
42
+
| **Authorization UI** | Browser Redirect | Browser Redirect | WebView/Browser |
43
+
| `redirect_uri` | App URL (HTTPS) | App URL (HTTPS) | App Link (Android), Universal Link (iOS), or Client-specific URI scheme |
44
+
45
+
✅: Required
46
+
47
+
❌: Forbidden
48
+
49
+
PKCE: Proof Key for Code Exchange ([RFC 7636](https://datatracker.ietf.org/doc/html/rfc7636))
50
+
51
+
PAR: Pushed Authorization Requests ([RFC 9126](https://datatracker.ietf.org/doc/html/rfc9126))
52
+
53
+
DPoP: Demonstrating Proof of Possession ([RFC 9449](https://datatracker.ietf.org/doc/html/rfc9449))
54
+
55
+
Client Metadata: OAuth Client ID Metadata Document ([`draft-parecki-oauth-client-id-metadata-document`](https://datatracker.ietf.org/doc/draft-parecki-oauth-client-id-metadata-document/))
56
+
57
+
Other architectures are possible. For example, a mobile app which uses a web service to mediate client authentication and refresh tokens, or a web service could act as a "Public" client. This guide focuses on the most common use-cases.
58
+
59
+
OAuth is not currently recommended as an auth solution for for "headless" clients, such as command-line tools or bots.
60
+
61
+
## Components
62
+
63
+
OAuth 2 is a framework for designing authentication systems, not a single standard or API to implement. This section describes the standards used in the specific atproto "profile" of OAuth, and components that a typical client will need to implement.
64
+
65
+
### Client and Server Metadata
66
+
67
+
The atproto network is decentralized: there are many independent PDS instances and many client apps. OAuth needs to facilitate any client app being authorized against any PDS instance, without prior registration or coordination between users, developers, or service operators. The atproto OAuth profile makes this possible by combining public client metadata and public authorization server metadata.
68
+
69
+
All atproto OAuth clients must publish a client metadata JSON document on the public web. The `client_id`, which globally identifies the client software instance, is the fully-qualified `https://` URL at which this JSON document can be accessed.
70
+
71
+
"Confidential" clients (Web Services) include public cryptographic keys in their client metadata which can be used during an authentication request to verify the client. It is important that such clients be able to remove the public keys from their client metadata in the event that the corresponding secret key is compromised or leaked.
72
+
73
+
Client metadata fields include:
74
+
75
+
- `client_id` (string, required): must exactly match the full URL used to fetch the client metadata JSON itself
76
+
- `application_type` (string, optional): must be one of `web` (default) or `native`
77
+
- `grant_types` (array of strings, required): usually `authorization_code` and `refresh_token`
78
+
- `scope` (string, sub-strings space-separated, required): any scope values which *might* be requested by this client are declared here. The `atproto` scope is required.
79
+
- `response_types` (array of strings, required): usually just `code`.
80
+
- `redirect_uris` (array of strings, required): the fully-qualified redirect/callback URL is declared here.
81
+
- `dpop_bound_access_tokens` (boolean, required): must be `true` (DPoP is mandatory)
82
+
- `token_endpoint_auth_method` (string, optional): confidential clients must set this to `private_key_jwt`.
83
+
- `token_endpoint_auth_signing_alg` (string, optional): confidential client set this to `ES256`
84
+
- `jwks` (object with array of JWKs, optional) or `jwks_uri` (string URL, optional): confidential clients must supply at least one public key in JWK format for use with JWT client authentication.
85
+
86
+
And some optional (but recommended) metadata fields:
87
+
88
+
- `client_name` (string, optional): human-readable name of the client
89
+
- `client_uri` (string, optional): not to be confused with `client_id`, this is a homepage URL for the client. If provided, the `client_uri` must have the same hostname as `client_id`.
90
+
- `logo_uri` (string, optional): HTTP URL to client logo
91
+
- `tos_uri` (string, optional): HTTP URL to human-readable terms of service ("ToS") for the client
92
+
- `policy_uri` (string, optional): HTTP URL to human-readable privacy policy for the client
93
+
94
+
Here is an example Browser App client metadata file, that would need to be hosted at [https://app.example.com/oauth/client-metadata.json](https://app.example.com/oauth/client-metadata.json) (served with Content-Type `application/json` and HTTP status 200, no redirects):
95
+
96
+
```prism
97
+
{
98
+
"client_id": "https://app.example.com/oauth/client-metadata.json",
99
+
"application_type": "web",
100
+
"client_name": "Example Browser App",
101
+
"client_uri": "https://app.example.com",
102
+
"dpop_bound_access_tokens": true,
103
+
"grant_types": [
104
+
"authorization_code",
105
+
"refresh_token"
106
+
],
107
+
"redirect_uris": [
108
+
"https://app.example.com/oauth/callback"
109
+
],
110
+
"response_types": [
111
+
"code"
112
+
],
113
+
"scope": "atproto transition:generic",
114
+
"token_endpoint_auth_method": "none"
115
+
}
116
+
```
117
+
118
+
PDS instances (and any supporting servers) also publish public JSON documents containing authorization server metadata.
119
+
120
+
In OAuth terminology, the PDS is a "Resource Server" which authenticated requests are made to. The PDS publishes a "protected resource metadata" file at the well-known HTTPS path `/.well-known/oauth-protected-resource`. This contains a field `authorization_servers` with an array of URLs indicating the "Authorization Server" location (the origin or "issuer"). In OAuth terminology, the "Authorization Server" is responsible for authenticating the user and providing authorization tokens. The authorization server might be the PDS itself (same origin), or it might be separate. For example, an "entryway" service in large multi-PDS deployments, or an delegated authorization provider. The authorization server metadata endpoint is `/.well-known/oauth-authorization-server`. The response includes the following fields relevant to clients:
121
+
122
+
- `issuer` (string, required): the "origin" URL of the Authorization Server. Must be a valid URL, with `https` scheme, matching the origin of URL used to fetch this document. There must be no path segments.
123
+
- `pushed_authorization_request_endpoint` (string, required): URL for Pushed Authentication Requests (PAR)
124
+
- `authorization_endpoint` (string, required): URL for authorization interface
125
+
- `token_endpoint` (string, required): URL for token requests
126
+
- `scopes_supported` (space-separated string, required): must include `atproto`, to confirm that this server supports the atproto profile of OAuth. If supporting the transitional grants, they should be included here as well.
127
+
128
+
There is a longer list of fields that clients may want to confirm/validate in the atproto OAuth specification.
129
+
130
+
Fetches of any of these metadata documents should be made using a hardened HTTP client, as described below.
131
+
132
+
### PKCE
133
+
134
+
All clients must implement PKCE. In practical terms, this means:
135
+
136
+
- creating a unique random value at the start of the session
137
+
- including a "challenge code" derived from this value during the Authentication Request
138
+
- verifying the value during the first token request
139
+
140
+
The "code challenge" method used is `S256`, which is the most popular PKCE challenge method. The transform involves a relatively simple SHA-256 hash and base64url string encoding. It can be implemented from scratch if needed, or sometimes OAuth libraries provide a helpers. The code value is a set of 32 to 96 random bytes, encoded in base64url (resulting in 43 or more string-encoded characters).
141
+
142
+
For example, given a randomly generated "verifier" token, whose base64url representation is: `dBjftJeZ4CVP-mB92K27uhbUJU1p1r_wW1gFWFOEjXk`
143
+
144
+
The `S256` code challenge is: `E9Melhoa2OwvFrEMTJguCHaoeK1t8URWbuGJSstw-cM`
145
+
146
+
### PAR
147
+
148
+
Pushed Authentication Requests (PAR) are required for all client types. This means that the client makes an HTTP POST request to the PDS/entryway PAR endpoint with all the authentication requests parameters as an HTTP form-encoded body, and receives a request token in response. The client then redirects the browser to the authorization endpoint with the token (and `client_id`) as a query parameter, instead of passing a long list of request fields as query parameters.
149
+
150
+
The PAR request is submitted to the `pushed_authorization_request_endpoint` (from server metadata), and must use `Content-Type: application/x-www-form-urlencoded`.
151
+
152
+
A successful response body will be a JSON object including the field `request_uri` (not to be confused with `redirect_uri`).
153
+
154
+
### DPoP
155
+
156
+
Clients must use DPoP to bind auth tokens to a specific client device or server. DPoP nonces, provided by the auth server, must be used.
157
+
158
+
Clients generate a new DPoP cryptographic keypair *for each auth session*, and retain the keypair for the duration of the auth session. DPoP keypairs should never be exported or moved between devices, and should never be reused across users or between sessions for the same user. Client must start DPoP at the initial authorization request (PAR).
159
+
160
+
`ES256` (NIST "P-256") is the cryptographic algorithm/curve which must be supported by all clients and auth servers. Browser Apps should use the WebCrypto API to generate non-exportable keypairs, which can be stored in IndexedDB to persist across browser sessions (not to be confused with OAuth sessions). Other clients may find implementations of this cryptographic system in generic JWT libraries, or in generic cryptographic libraries for their language or environment. DPoP is also increasingly required as part of OAuth profiles and will hopefully be supported by generic OAuth libraries.
161
+
162
+
DPoP involves setting a HTTP Header (`DPoP`) on every token request and every authorized request to the PDS. The header value is a self-signed JWT. There is a unique random field (`jti`) in the body, and JWTs are generated and signed uniquely for every request (DPoP proof JWTs can not be reused between requests).
163
+
164
+
The server returns the current DPoP nonce in the `DPoP-Nonce` HTTP header in every response. Nonce values may be shared across all users and sessions on the server, or may be scoped to individual users and sessions. Nonces may be shared between access token use (PDS requests) and authorization server requests (PDS or entryway), but they may be distinct servers, so clients should always track DPoP nonces separately for the two uses. Nonces change periodically, with a rotation period chosen by the server. Clients should persist the DPoP nonce for each session, and update the persisted value when a response is received with a different value.
165
+
166
+
If the nonce is missing (because it isn't known yet), or has become outdated, the server will return an HTTP 401 ("Unauthorized") response, indicating the error type as `use_dpop_nonce` and including the current nonce value in the `DPoP-Nonce` header. The Authorization Server (entryway or PDS, when doing PAR or token requests) indicates the error type with a JSON object body with the `error` field set to `use_dpop_nonce`. The Resource Server (PDS, when making authorized requests) indicates the error type using the `WWW-Authenticate` header with an `error` value set to `use_dpop_nonce`. For example:
167
+
168
+
```prism
169
+
HTTP/1.1 401 Unauthorized
170
+
WWW-Authenticate: DPoP error="use_dpop_nonce", error_description="Resource server requires nonce in DPoP proof"
171
+
DPoP-Nonce: eyJ7S_zG.eyJH0-Z.HX4w-7v
172
+
```
173
+
174
+
For other server type, the client can retry the request with a new DPoP proof JWT including the nonce value. The client discovers the initial nonce for each server by doing this request/error/retry cycle at least once. Servers will usually accept stale/old nonce values for a short time window to reduce errors-and-retries caused by clients making multiple concurrent authorized requests. Ideally the request/error/retry cycle does not need to happen again, though clients should be ready for it at any time (eg, if the nonce has rotated multiple times between requests).
175
+
176
+
When making DPoP requests to token endpoint:
177
+
178
+
- JWT header fields must be:
179
+
- `typ`: `dpop+jwt`
180
+
- `alg`: `ES256`
181
+
- `jwk`: DPoP public key in JSON Web Key (JWK) string format
182
+
- JWT fields should include:
183
+
- `jti`: random token string (unique per request)
184
+
- `htm`: HTTP method (eg, "POST" or "GET")
185
+
- `htu`: HTTP request URL
186
+
- `iat`: current UNIX time (integer seconds)
187
+
- `exp`: optional, expiration UNIX time (integer seconds) in the near future
188
+
- `nonce`: server-provided nonce string. If nonce isn’t known yet, don’t include this field, then receive the nonce via header in the error response
189
+
- JWT string in the `DPoP` HTTP header
190
+
191
+
When making DPoP requests to PDS endpoints:
192
+
193
+
- same JWT header fields as above
194
+
- same JWT body fields as above, plus:
195
+
- `iss`: authorization server issuer
196
+
- `ath`: hash of the access token, using the same mechanism as the `S256` PKCE challenge hash
197
+
- JWT string in the `DPoP` HTTP header
198
+
- access token in the `Authorization` HTTP header, with type `DPoP` (so header looks like `Authorization: DPoP <token>`)
199
+
200
+
### Confidential Client Authentication
201
+
202
+
Confidential clients declare their authentication keypair by including the public key in their client metadata (in the `jwks` or `jwks_uri` fields), and then authenticate by including a JWT bearer assertion in requests to the authorization server. They are required for the authorization request (PAR) and all token requests (both the initial token request and any subsequent refresh requests).
203
+
204
+
The client assertion type is `urn:ietf:params:oauth:client-assertion-type:jwt-bearer`.
205
+
206
+
When constructing an assertion JWT:
207
+
208
+
- assertion JWTs must not be reused: they include a random token, and must be generated and signed on every relevant request
209
+
- the `ES256` cryptographic system must be supported by all clients and auth servers
210
+
- JWT header fields include:
211
+
- `alg`: `ES256`
212
+
- `kid`: string indicating which of the declared keys (in JWKS) is being used
213
+
- JWT body fields include:
214
+
- `iss`: the `client_id`
215
+
- `sub`: the `client_id`
216
+
- `aud`: the authorization server issuer URL (origin)
217
+
- `jti`: randomly generated token string
218
+
- `iat`: current UNIX time (integer seconds)
219
+
220
+
### Token Management
221
+
222
+
Long-lived clients will need to manage access token lifetimes and periodic refresh token requests. This is functionality that is sometimes implemented in generic OAuth libraries. Care must be taken to ensure that concurrent resource requests don't result in concurrent token refresh requests, which could result in errors and loss of the overall auth session (requiring re-authorization).
223
+
224
+
Access and refresh tokens should never be copied or shared across end devices. They should not be stored in session cookies.
225
+
226
+
### Hardened HTTP Client (SSRF)
227
+
228
+
Clients need to make a several HTTP network requests using URLs provided by unknown parties. These raise a number of security concerns, including network requests to local or private IP addresses (SSRF), and trivial Denial of Service attacks (large response bodies, slow responses, etc).
229
+
230
+
A good way to mitigate these issues is to use or implement a hardened HTTP client. It should set appropriate timeouts and resource limits, validate URLs, and check that resolve domain names don't point to protected or local IP addresses.
231
+
232
+
### Account or Server Identifier
233
+
234
+
Clients can start an auth flow in one of two ways:
235
+
236
+
- starting with an atproto account identifier: handle or DID
237
+
- starting with a server URL or hostname (PDS or entryway)
238
+
239
+
One use case for starting with a server URL instead of an account identifier is when the user does not remember their full account handle or only knows their account email. Another is for authentication when a user’s handle is broken. The user still needs to know their hosting provider in these situations.
240
+
241
+
When starting with an account identifier, the client must resolve the atproto identity to a DID document. If starting with a handle, it is critical (mandatory) to bidirectionally verify the handle by checking that the DID document claims the handle (see atproto Handle specification). All handle resolution techniques and all atproto-blessed DID methods must be supported to ensure interoperability with all accounts.
242
+
243
+
In some client environments, it may be difficult to resolve all identity types. For example, handle resolution may involve DNS TXT queries, which are not directly supported from browser apps. Client implementations might use alternative techniques (such as DNS-over-HTTPS) or could make use of a supporting web service to resolve identities.
244
+
245
+
If the auth flow instead starts with a server (hostname or URL), the client will first attempt to fetch Resource Server metadata (and resolve to Authorization Server if found) and then attempt to fetch Authorization Server metadata. If either is successful, the client will end up with an identified Authorization Server. The Authorization Request and flow will proceed without a `login_hint` or account identifier being bound to the session, but the Authorization Server `issuer` will be bound to the session.
246
+
247
+
Either way, by the end of the authorization flow it will be important to resolve the DID of the authorized account and verify that it is consistent with the authorization server being talked to, and that the server granted access tokens for the expected account.
248
+
249
+
### Authorization Request
250
+
251
+
The client next makes a Pushed Authorization Request via HTTP POST request to the `pushed_authorization_request_endpoint`. Notable details include:
252
+
253
+
- a randomly generated `state` token is required, and will be used to reference this authorization request with the subsequent response callback
254
+
- PKCE is required, so a secret value is generated and stored, and a derived challenge is included in the request
255
+
- `scopes` value is included here, and must include `atproto`
256
+
- for confidential clients, a `client_assertion` is included, with type `jwt-bearer`, signed using the secret client authentication key
257
+
- the client generates a new DPoP key for the user/session and uses it starting with the PAR request
258
+
- if the auth flow started with an account identifier, the client should pass that starting identifier via the `login_hint` field
259
+
260
+
The initial response will be a DPoP error, with the server nonce included in an HTTP header. The client includes this nonce in a new DPoP JWT and retries the request.
261
+
262
+
The Authorization Server will receive the PAR request and use the `client_id` URL to resolve the client metadata document. If all goes well, the server returns a `request_uri` token to the client.
263
+
264
+
The client persists information about the session to some form of storage. This might be a database (for a web service backend) or web platform storage like IndexedDB (for a browser app).
265
+
266
+
Then the client redirects the user via browser to the Authorization Server’s auth endpoint, including the `request_uri` as a URL parameter.
267
+
268
+
The user will authenticate with the server and approve the authorization request, using the "authorization interface" on the PDS/entryway.
269
+
270
+
### Callback and Access Token Request
271
+
272
+
The server redirects the user back to the `redirect_uri` (from the authorization interface), with some query parameters included:
273
+
274
+
- `state`: matching `state` included in the authorization request
275
+
- `iss`: the URL (origin) of the authorization server
276
+
- `code`: the authorization code which can be used for an initial token request
277
+
278
+
The client can now make an initial token request to the authorization server token endpoint. It includes the `code` and PKCE code verification. Confidential clients must also include a client assertion (JWT signed with the client keypair).
279
+
280
+
This request uses DPoP, using the authorization server nonce saved after the earlier authorization request.
281
+
282
+
The server will return a JSON object with a set of tokens (`access_token` and `refresh_token`). It will also include a `sub` field containing the atproto account DID, and authorized `scope`.
283
+
284
+
It is **critical** for the client to verify that the `sub` DID matches the account expected. If the entire auth flow started with an account identifier (handle or DID), this value is compared against the original DID. If the auth flow started with a PDS/entryway URL, the client should now resolve the DID document, and verify that the declared PDS instances is consistent with the authorization server.
285
+
286
+
Authentication-only clients can end the flow here.
287
+
288
+
### PDS Requests and Token Refresh
289
+
290
+
Using the access token, clients are now able to make authorized requests to the PDS. They must use DPoP for all such requests, with a separate server-provided nonce, along with the access token.
291
+
292
+
Tokens (both access and refresh) will need to be periodically "refreshed" by subsequent request to the Authorization Server token endpoint.
+196
contextual info for claude/Quick start guide to building applications on AT Protocol - AT Protocol.md
+196
contextual info for claude/Quick start guide to building applications on AT Protocol - AT Protocol.md
···
1
+
---
2
+
title: "Quick start guide to building applications on AT Protocol - AT Protocol"
3
+
source: "https://atproto.com/guides/applications"
4
+
author:
5
+
- "[[AT Protocol]]"
6
+
published:
7
+
created: 2025-03-07
8
+
description: "In this guide, we're going to build a simple multi-user app that publishes your current \"status\" as an emoji."
9
+
tags:
10
+
- "clippings"
11
+
---
12
+
[
13
+
14
+
Find the source code for the example application on GitHub.
15
+
16
+
](https://github.com/bluesky-social/statusphere-example-app)
17
+
18
+
In this guide, we're going to build a simple multi-user app that publishes your current "status" as an emoji. Our application will look like this:
19
+
20
+
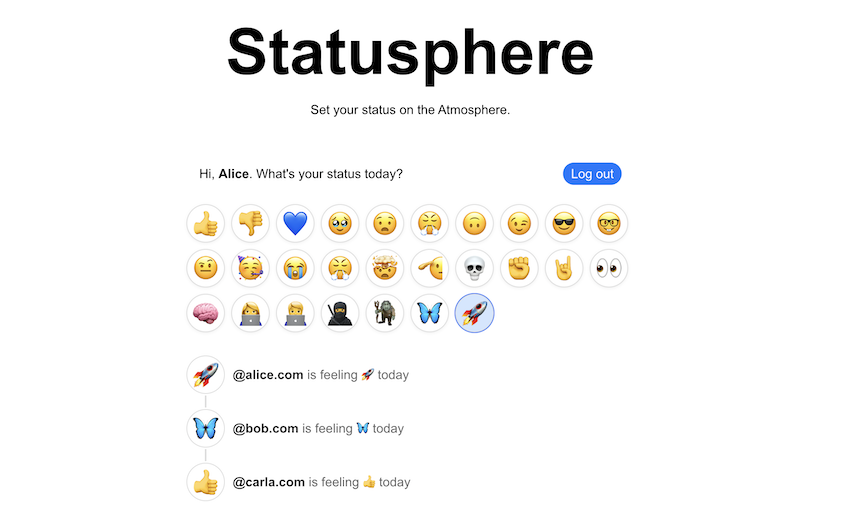
21
+
22
+
We will cover how to:
23
+
24
+
- Signin via OAuth
25
+
- Fetch information about users (profiles)
26
+
- Listen to the network firehose for new data
27
+
- Publish data on the user's account using a custom schema
28
+
29
+
We're going to keep this light so you can quickly wrap your head around ATProto. There will be links with more information about each step.
30
+
31
+
Data in the Atmosphere is stored on users' personal repos. It's almost like each user has their own website. Our goal is to aggregate data from the users into our SQLite DB.
32
+
33
+
Think of our app like a Google. If Google's job was to say which emoji each website had under `/status.json`, then it would show something like:
34
+
35
+
- `nytimes.com` is feeling 📰 according to `https://nytimes.com/status.json`
36
+
- `bsky.app` is feeling 🦋 according to `https://bsky.app/status.json`
37
+
- `reddit.com` is feeling 🤓 according to `https://reddit.com/status.json`
38
+
39
+
The Atmosphere works the same way, except we're going to check `at://` instead of `https://`. Each user has a data repo under an `at://` URL. We'll crawl all the user data repos in the Atmosphere for all the "status.json" records and aggregate them into our SQLite database.
40
+
41
+
> `at://` is the URL scheme of the AT Protocol. Under the hood it uses common tech like HTTP and DNS, but it adds all of the features we'll be using in this tutorial.
42
+
43
+
Start by cloning the repo and installing packages.
44
+
45
+
Our repo is a regular Web app. We're rendering our HTML server-side like it's 1999. We also have a SQLite database that we're managing with [Kysely](https://kysely.dev/).
46
+
47
+
Our starting stack:
48
+
49
+
- Typescript
50
+
- NodeJS web server ([express](https://expressjs.com/))
51
+
- SQLite database ([Kysely](https://kysely.dev/))
52
+
- Server-side rendering ([uhtml](https://www.npmjs.com/package/uhtml))
53
+
54
+
With each step we'll explain how our Web app taps into the Atmosphere. Refer to the codebase for more detailed code — again, this tutorial is going to keep it light and quick to digest.
55
+
56
+
When somebody logs into our app, they'll give us read & write access to their personal `at://` repo. We'll use that to write the status json record.
57
+
58
+
We're going to accomplish this using OAuth ([spec](https://github.com/bluesky-social/proposals/tree/main/0004-oauth)). Most of the OAuth flows are going to be handled for us using the [@atproto/oauth-client-node](https://github.com/bluesky-social/atproto/tree/main/packages/oauth/oauth-client-node) library. This is the arrangement we're aiming toward:
59
+
60
+
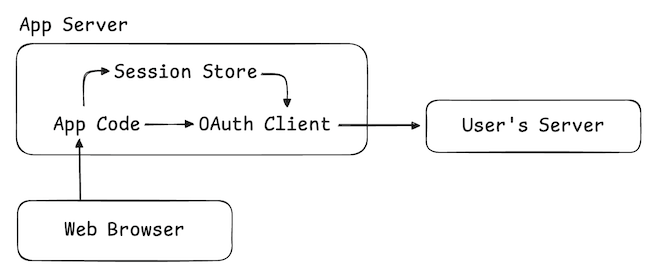
61
+
62
+
When the user logs in, the OAuth client will create a new session with their repo server and give us read/write access along with basic user info.
63
+
64
+
65
+
66
+
Our login page just asks the user for their "handle," which is the domain name associated with their account. For [Bluesky](https://bsky.app/) users, these tend to look like `alice.bsky.social`, but they can be any kind of domain (eg `alice.com`).
67
+
68
+
When they submit the form, we tell our OAuth client to initiate the authorization flow and then redirect the user to their server to complete the process.
69
+
70
+
This is the same kind of SSO flow that Google or GitHub uses. The user will be asked for their password, then asked to confirm the session with your application.
71
+
72
+
When that finishes, the user will be sent back to `/oauth/callback` on our Web app. The OAuth client will store the access tokens for the user's server, and then we attach their account's [DID](https://atproto.com/specs/did) to the cookie-session.
73
+
74
+
With that, we're in business! We now have a session with the user's repo server and can use that to access their data.
75
+
76
+
Why don't we learn something about our user? In [Bluesky](https://bsky.app/), users publish a "profile" record which looks like this:
77
+
78
+
You can examine this record directly using [atproto-browser.vercel.app](https://atproto-browser.vercel.app/). For instance, [this is the profile record for @bsky.app](https://atproto-browser.vercel.app/at?u=at://did:plc:z72i7hdynmk6r22z27h6tvur/app.bsky.actor.profile/self).
79
+
80
+
We're going to use the [Agent](https://github.com/bluesky-social/atproto/tree/main/packages/api) associated with the user's OAuth session to fetch this record.
81
+
82
+
When asking for a record, we provide three pieces of information.
83
+
84
+
- **repo** The [DID](https://atproto.com/specs/did) which identifies the user,
85
+
- **collection** The collection name, and
86
+
- **rkey** The record key
87
+
88
+
We'll explain the collection name shortly. Record keys are strings with [some restrictions](https://atproto.com/specs/record-key#record-key-syntax) and a couple of common patterns. The `"self"` pattern is used when a collection is expected to only contain one record which describes the user.
89
+
90
+
Let's update our homepage to fetch this profile record:
91
+
92
+
With that data, we can give a nice personalized welcome banner for our user:
93
+
94
+

95
+
96
+
You can think of the user repositories as collections of JSON records:
97
+
98
+
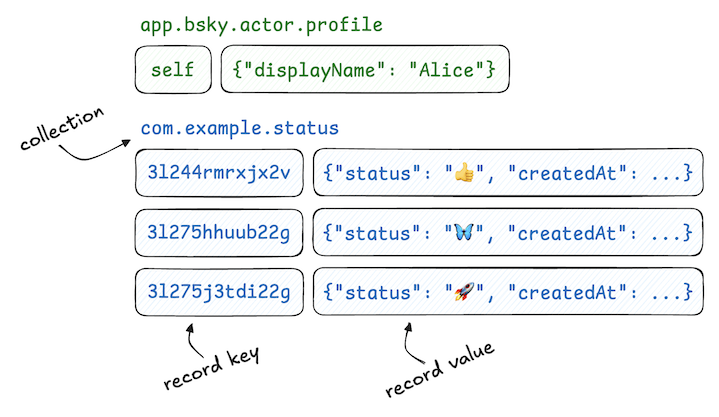
99
+
100
+
Let's look again at how we read the "profile" record:
101
+
102
+
We write records using a similar API. Since our goal is to write "status" records, let's look at how that will happen:
103
+
104
+
Our `POST /status` route is going to use this API to publish the user's status to their repo.
105
+
106
+
Now in our homepage we can list out the status buttons:
107
+
108
+
And here we are!
109
+
110
+

111
+
112
+
Repo collections are typed, meaning that they have a defined schema. The `app.bsky.actor.profile` type definition [can be found here](https://github.com/bluesky-social/atproto/blob/main/lexicons/app/bsky/actor/profile.json).
113
+
114
+
Anybody can create a new schema using the [Lexicon](https://atproto.com/specs/lexicon) language, which is very similar to [JSON-Schema](http://json-schema.org/). The schemas use [reverse-DNS IDs](https://atproto.com/specs/nsid) which indicate ownership. In this demo app we're going to use `xyz.statusphere` which we registered specifically for this project (aka statusphere.xyz).
115
+
116
+
> ### Why create a schema?
117
+
>
118
+
> Schemas help other applications understand the data your app is creating. By publishing your schemas, you make it easier for other application authors to publish data in a format your app will recognize and handle.
119
+
120
+
Let's create our schema in the `/lexicons` folder of our codebase. You can [read more about how to define schemas here](https://atproto.com/guides/lexicon).
121
+
122
+
Now let's run some code-generation using our schema:
123
+
124
+
This will produce Typescript interfaces as well as runtime validation functions that we can use in our app. Here's what that generated code looks like:
125
+
126
+
Let's use that code to improve the `POST /status` route:
127
+
128
+
So far, we have:
129
+
130
+
- Logged in via OAuth
131
+
- Created a custom schema
132
+
- Read & written records for the logged in user
133
+
134
+
Now we want to fetch the status records from other users.
135
+
136
+
Remember how we referred to our app as being like Google, crawling around the repos to get their records? One advantage we have in the AT Protocol is that each repo publishes an event log of their updates.
137
+
138
+

139
+
140
+
Using a [Relay service](https://docs.bsky.app/docs/advanced-guides/federation-architecture#relay) we can listen to an aggregated firehose of these events across all users in the network. In our case what we're looking for are valid `xyz.statusphere.status` records.
141
+
142
+
Let's create a SQLite table to store these statuses:
143
+
144
+
Now we can write these statuses into our database as they arrive from the firehose:
145
+
146
+
You can almost think of information flowing in a loop:
147
+
148
+
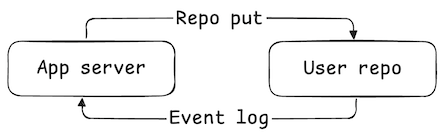
149
+
150
+
Applications write to the repo. The write events are then emitted on the firehose where they're caught by the apps and ingested into their databases.
151
+
152
+
Why sync from the event log like this? Because there are other apps in the network that will write the records we're interested in. By subscribing to the event log, we ensure that we catch all the data we're interested in — including data published by other apps!
153
+
154
+
Now that we have statuses populating our SQLite, we can produce a timeline of status updates by users. We also use a [DID](https://atproto.com/specs/did)\-to-handle resolver so we can show a nice username with the statuses:
155
+
156
+
Our HTML can now list these status records:
157
+
158
+

159
+
160
+
As a final optimization, let's introduce "optimistic updates."
161
+
162
+
Remember the information flow loop with the repo write and the event log?
163
+
164
+

165
+
166
+
Since we're updating our users' repos locally, we can short-circuit that flow to our own database:
167
+
168
+
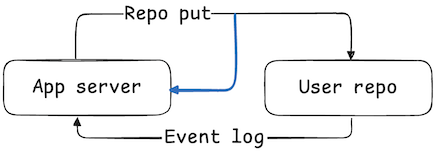
169
+
170
+
This is an important optimization to make, because it ensures that the user sees their own changes while using your app. When the event eventually arrives from the firehose, we just discard it since we already have it saved locally.
171
+
172
+
To do this, we just update `POST /status` to include an additional write to our SQLite DB:
173
+
174
+
You'll notice this code looks almost exactly like what we're doing in `ingester.ts`.
175
+
176
+
In this tutorial we've covered the key steps to building an atproto app. Data is published in its canonical form on users' `at://` repos and then aggregated into apps' databases to produce views of the network.
177
+
178
+
When building your app, think in these four key steps:
179
+
180
+
- Design the [Lexicon](https://atproto.com/guides/#) schemas for the records you'll publish into the Atmosphere.
181
+
- Create a database for aggregating the records into useful views.
182
+
- Build your application to write the records on your users' repos.
183
+
- Listen to the firehose to aggregate data across the network.
184
+
185
+
Remember this flow of information throughout:
186
+
187
+

188
+
189
+
This is how every app in the Atmosphere works, including the [Bluesky social app](https://bsky.app/).
190
+
191
+
If you want to practice what you've learned, here are some additional challenges you could try:
192
+
193
+
- Sync the profile records of all users so that you can show their display names instead of their handles.
194
+
- Count the number of each status used and display the total counts.
195
+
- Fetch the authed user's `app.bsky.graph.follow` follows and show statuses from them.
196
+
- Create a different kind of schema, like a way to post links to websites and rate them 1 through 4 stars.
+43
contextual info for claude/Resolving Identities Bluesky.md
+43
contextual info for claude/Resolving Identities Bluesky.md
···
1
+
---
2
+
title: "Resolving Identities | Bluesky"
3
+
source: "https://docs.bsky.app/docs/advanced-guides/resolving-identities"
4
+
author:
5
+
published:
6
+
created: 2025-03-07
7
+
description: "Identities in the Bluesky network consist of multiple parts:"
8
+
tags:
9
+
- "clippings"
10
+
---
11
+
Identities in the Bluesky network consist of multiple parts:
12
+
13
+
- **DIDs**: persistent, long-term identifiers for every account. Usually look like `did:plc:ewvi7nxzyoun6zhxrhs64oiz`. Details are in the [atproto specs](https://atproto.com/specs/did)
14
+
- **Handles**: updatable, human-readable usernames for accounts. Look like `atproto.bsky.social` or `atproto.com`. Details are in the [atproto specs](https://atproto.com/specs/handle)
15
+
- **Profile records**: updatable metadata including a display name, avatar picture, and description. Lexicon is `app.bsky.actor.profile`
16
+
17
+
## For Clients
18
+
19
+
Bluesky client apps don't need to do identity resolution very often, because Bluesky API responses often hydrate in identity and profile metadata when needed.
20
+
21
+
When they do need to resolve identities, they may be able to get by with the PDS-provided `com.atproto.identity.resolveHandle`, or future endpoints to facilitate identity resolution server-side (possibly with caching).
22
+
23
+
Otherwise, they will need to do direct resolution. Browser-based clients can not generally make arbitrary DNS queries, so the `com.atproto.identity.resolveHandle` is used for that type of handle resolution.
24
+
25
+
## For Backend Services
26
+
27
+
While it is possible in some cases to simply trust infrastructure like the Relay to pass through identity metadata over the firehose, more independent service providers are likely to resolve identities (handles and DIDs) on their own. This ensures handle/DID mappings are valid, and provides direct access to cryptographic keys for validating signatures.
28
+
29
+
The process of resolving identities usually involves a handful of DNS and HTTPS network requests, and in the common case should succeed within a couple hundred milliseconds. The atproto specifications include details on resolving `did:web` and `did:plc` identifiers, and resolving handles using both the DNS TXT and HTTPS `/.well-known/` mechanism. Services should support all of these methods.
30
+
31
+
For `did:plc` specifically, implementations should decide whether to trust the PLC directory to return accurate DID documents, or to fetch the operation log (or even audit log) and fully re-validate the operations.
32
+
33
+
It is strongly recommended to use identity caches for large backend services. Cached information needs to be re-validated periodically; we recommend a maximum TTL of 24 hours for core identity metadata. It is often helpful to cache failures as well as successful lookups, but shorter TTLs (on the order of 5 minutes) are better in this case. For example, if a handle is found to be invalid, don't continuously retry several times a second, but don't wait a full 24 hours before retrying either.
34
+
35
+
A few more tips on identity caching at scale:
36
+
37
+
- it may be appropriate to retry identity resolution when account data validation fails in certain ways. For example, if a commit signatures fails to validate, it might be worth purging any identity cache and directly re-resolving the DID to see if the signing keys were updated. If feed generator API requests fail, an intermediate service might want to re-resolve the service DID document to see if the service endpoint moved.
38
+
- the DID PLC registry has a global operation log API endpoint, which can be used to poll for identity updates. The Relay firehose also includes identity update events. Both of these feeds can be used to proactively update identity caches while making fewer network calls
39
+
- remember that the global DNS system has it's own caching and TTL behaviors. In some cases it may be beneficial to retry handle resolutions "harder", for example using some degree of recursive resolution, or an alternative DNS server
40
+
- depending on the use-case, services might want to proactively re-validate identities when they expire, or they might wait to "read-through" the cache
41
+
- use best-practices for HTTP requests: reasonable timeouts and retries, exponential backoff, handling HTTP status codes correctly (including 429 "Rate-Limit Exceeded" and 404 "Not Found")
42
+
43
+
Backend services generally don't always need access to Bluesky profile records. One case where they may this data is if they are providing public web access to user data, and want to respect the public web opt-out (`!no-unauthenticated` self-label on the profile record).
+168
contextual info for claude/Sync - AT Protocol.md
+168
contextual info for claude/Sync - AT Protocol.md
···
1
+
---
2
+
title: "Sync - AT Protocol"
3
+
source: "https://atproto.com/specs/sync"
4
+
author:
5
+
- "[[AT Protocol]]"
6
+
published:
7
+
created: 2025-03-07
8
+
description: "Firehose and other data synchronization mechanisms."
9
+
tags:
10
+
- "clippings"
11
+
---
12
+
## Data Synchronization
13
+
14
+
One of the main design goals of atproto (the "Authenticated Transfer Protocol") is to reliably distribute public content between independent network services. This data transfer should be trustworthy (cryptographicly authenticated) and relatively low-latency even at large scale. It is also important that new participants can join the network at any time and “backfill” prior content.
15
+
16
+
This section describes the major data synchronization features in atproto. The primary real-time data synchronization mechanism is repository event streams, commonly referred to as "firehoses". The primary batch data transfer mechanism is repository exports as CAR files. These two mechanisms can be combined in a "bootstrapping" process which result in a live-synchronized copy of the network.
17
+
18
+
As described in the repository spec, each commit to a repository has a *revision* number, in TID syntax. The revision number must always increase between commits for the same account, even if the account is migrated between hosts or has a period of inactivity in the network. Revision numbers can be used as a logical clock to aid synchronization of individual accounts. To keep this simple, it is recommended to use the current time as a TID for each commit, including the initial commit when creating a new account. Services should reject or ignore revision numbers corresponding to future timestamps (beyond a short fuzzy time drift window). Network services can track the commit revision for every account they have seen, and use this to verify synchronization progress. Services which synchronize data can include the most-recently-processed revision in HTTP responses to API requests from the account in question, in the `Atproto-Repo-Rev` HTTP response header. This allows clients (and users) to detect if the response is up-to-date with the actual repository, and detect any problems with synchronization.
19
+
20
+
The repository event stream (`com.atproto.sync.subscribeRepos`, also called the "firehose") is an [Event Stream](https://atproto.com/specs/event-stream) which broadcasts updates to repositories (`#commit` events), handles and DID documents (`#identity`), and account hosting status (`#account`). PDS hosts provide a single stream with updates for all locally-hosted accounts. "Relays" are network services which subscribe to one or more repo streams (eg, multiple PDS instances) and aggregate them in to a single combined repo stream. The combined stream has the same structure and event types. A Relay which aggregates nearly all accounts from nearly all PDS instances in the network (possibly through intermediate relays) outputs a “full-network” firehose. Relays often mirror and can re-distribute the repository contents, though their core functionality is to verify content and output a unified firehose.
21
+
22
+
In most cases the repository data synchronized over the firehose is self-certifying (contains verifiable signatures), and consumers can verify content without making additional requests directly to account PDS instances. It is possible for services to redact events from the firehose, such that downstream services would not be aware of new content.
23
+
24
+
Identity and account information is *not* self-certifying, and services may need need to verify independently. This usually means independent DID and [handle resolution](https://atproto.com/specs/handle). Account hosting status might also be checked at account PDS hosts, to disambiguate hosting status at different pieces of infrastructure.
25
+
26
+
The event message types are declared in the `com.atproto.sync.subscribeRepos` Lexicon schema, and are summarized below. A few fields are the same for all event types (except for `repo` vs `did` for `#commit` events):
27
+
28
+
- `seq` (integer, required): used to ensure reliable consumption, as described in Event Streams
29
+
- `did` / `repo`(string with DID syntax, required): the account/identity associated with the event
30
+
- `time` (string with datetime syntax, required): an informal and non-authoritative estimate of when event was received. Intermediate services may decide to pass this field through as-is, or update to the current time
31
+
32
+
### `#identity` Events
33
+
34
+
Indicates that there *may* have been a change to the indicated identity (meaning the DID document or handle), and optionally what the current handle is. Does not indicate what changed, or reliably indicate what the current state of the identity is.
35
+
36
+
Event fields:
37
+
38
+
- `seq` (integer, required): same for all event types
39
+
- `did` (string with DID syntax, required): same for all event types
40
+
- `time` (string with datetime syntax, required): same for all event types
41
+
- `handle` (string with handle syntax, optional): the current handle for this identity. May be `handle.invalid` if the handle does not currently resolve correctly.
42
+
43
+
Presence or absence of the `handle` field does not indicate that it is the handle which has changed.
44
+
45
+
The semantics and expected behavior are that downstream services should update any cached identity metadata (including DID document and handle) for the indicated DID. They might mark caches as stale, immediately purge cached data, or attempt to re-resolve metadata.
46
+
47
+
Identity events are emitted on a "best-effort" basis. It is possible for the DID document or handle resolution status to change without any atproto service detecting the change, in which case an event would not be emitted. It is also possible for the event to be emitted redundantly, when nothing has actually changed.
48
+
49
+
Intermediate services (eg, relays) may chose to modify or pass through identity events:
50
+
51
+
- they may replace the handle with the result of their own resolution; or always remove the handle field; or always pass it through unaltered
52
+
- they may filter out identity events if they observe that identity has not actually changed
53
+
- they may emit identity events based on changes they became aware of independently (eg, via periodic re-validation of handles)
54
+
55
+
### `#account` Events
56
+
57
+
Indicates that there may have been a change in [Account Hosting status](https://atproto.com/specs/account) at the service which emits the event, and what the new status is. For example, it could be the result of creation, deletion, or temporary suspension of an account. The event describes the current hosting status, not what changed.
58
+
59
+
Event Fields:
60
+
61
+
- `seq` (integer, required): same for all event types
62
+
- `did` (string with DID syntax, required): same for all event types
63
+
- `time` (string with datetime syntax, required): same for all event types
64
+
- `active` (boolean, required): whether the repository is currently available and can be redistributed
65
+
- `status` (string, optional): string status code which describes the account state in more detail. Known values include:
66
+
- `takendown`: indefinite removal of the repository by a service provider, due to a terms or policy violation
67
+
- `suspended`: temporary or time-limited variant of `takedown`
68
+
- `deleted`: account has been deactivated, possibly permanently.
69
+
- `deactivated`: temporary or indefinite removal of all public data by the account themselves.
70
+
71
+
When coming from any service which redistributes account data, the event describes what the new status is *at that service*, and is authoritative in that context. In other words, the event is hop-by-hop for repository hosts and mirrors.
72
+
73
+
See the Account Hosting specification for more details.
74
+
75
+
### `#commit` Events
76
+
77
+
This event indicates that there has been a new repository commit for the indicated account. The event usually contains the "diff" of repository data, in the form of a CAR slice. See the [Repository specification](https://atproto.com/specs/repository) for details on "diffs" and the CAR file format.
78
+
79
+
See the Repository specification for more details around repo diffs.
80
+
81
+
Event Fields:
82
+
83
+
- `seq` (integer, required): same for all event types
84
+
- `repo` (string with DID syntax, required): the same as `did` for all other event types
85
+
- `time` (string with datetime syntax, required): same for all event types
86
+
- `rev` (string with TID syntax, required): the revision of the commit. Must match the `rev` in the commit block itself.
87
+
- `since` (string with TID syntax, nullable): indicates the `rev` of a preceding commit, which the the repo diff contains differences from
88
+
- `commit` (cid-link, required): CID of the commit object (in `blocks`)
89
+
- `tooBig` (boolean, required): if true, indicates that the repo diff was too large, and that `blocks`, `ops`, and complete `blobs` are not all included
90
+
- `blocks` (bytes, required): CAR "slice" for the corresponding repo diff. The commit object must always be included.
91
+
- `ops` (array of objects, required): list of record-level operations in this commit: specific records created, updated, deleted
92
+
- `blobs` (array of cid-link, required): set of new blobs (by CID) referenced by records in this commit
93
+
94
+
Commit events are broadcast when the account repository changes. Commits can be "empty", meaning no actual record content changed, and only the `rev` was incremented. They can contain a single record update, or multiple updates. Only the commit object, record blocks, and MST tree nodes are authenticated (signed): the `since`, `ops`, `blobs`, and `tooBig` fields are not self-certifying, and could in theory be manipulated, or otherwise be incorrect or incomplete.
95
+
96
+
If `since` is not included, the commit should include the full repo tree, or set the `tooBig` flag.
97
+
98
+
If the `tooBig` flag is set, then the amount of updated data was too much to be serialized in a single stream event message. Downstream services which want to maintain complete synchronized copies for the repo need to fetch the diff separately, as discussed below.
99
+
100
+
### Firehose Validation Best Practices
101
+
102
+
A service which does full validation of upstream events has a number of properties to track and check. For example, Relay instances should fully validate content from PDS instances before re-broadcasting.
103
+
104
+
Here is a summary of validation rules and behaviors:
105
+
106
+
- services should independently resolve identity data for each DID. They should ignore `#commit` events for accounts which do not have a functioning atproto identity (eg, lacking a signing key, or lacking a PDS service entry, or for which the DID has been tombstoned)
107
+
- services which subscribe directly to PDS instances should keep track of which PDS is authoritative for each DID. They should remember the host each subscription (WebSocket) is connected to, and reject `#commit` events for accounts if they come from a stream which does not correspond to the current account for that DID
108
+
- services should track account hosting status for each DID, and ignore `#commit` events for events which are not `active`
109
+
- services should verify commit signatures for each `#commit` event, using the current identity data. If the signature initially fails to verify, the service should refresh the identity metadata in case it had recently changed. Events with conclusively invalid signatures should be rejected.
110
+
- services should reject any event messages which exceed reasonable limits. A reasonable upper bound for producers is 5 MBytes (for any event stream message type). The `subscribeRepos` Lexicon also limits `blocks` to one million bytes, and `ops` to 200 entries. Commits with too much data must use the `tooBig` mechanism, though such commits should generally be avoided in the first place by breaking them up in to multiple smaller commits.
111
+
- services should verify that repository data structures are valid against the specification. Missing fields, incorrect MST structure, or other protocol-layer violations should result in events being rejected.
112
+
- services may apply rate-limits to identity, account, and commit events, and suspend accounts or upstream services which violate those limits. Rate limits might also be applied to recovery modes such as invalid signatures resulting in an identity refresh, `tooBig` events, missing or out-of-order commits, etc.
113
+
- services should ignore commit events with a `rev` lower or equal to the most recent processed `rev` for that DID, and should reject commit events with a `rev` corresponding to a future timestamp (beyond a clock drift window of a few minutes)
114
+
- services should check the `since` value in commit events, and if it is not consistent with the previous seen `rev` for that DID (see discussion in "Reliable Synchronization"), mark the repo as out-of-sync (similar to a `tooBig` commit event)
115
+
- data limits on records specifically should be verified. Events containing corrupt or entirely invalid records may be rejected. for example, a record not being CBOR at all, or exceeding normal data size limits.
116
+
- more subtle data validation of records may be enforced, or may be ignored, depending on the service. For example, unsupported CID hash types embedded in records should probably be ignored by Relays (even if they violate the atproto data model), but may result in the record or commit event being rejected by an AppView
117
+
- mirroring services, which retain a full copy of repository data, should verify that commit diffs leave the MST tree in a complete and valid state (eg, no missing records, no invalid MST nodes, commit CID would be reproducible if the MST structure was re-generated from scratch)
118
+
- Relays (specifically) should not validate records against Lexicons
119
+
120
+
This section describes some details on how to reliably subscribe to the firehose and maintain an existing synchronized mirror of the network.
121
+
122
+
Services should generally maintain a few pieces of state for all accounts they are tracking data from:
123
+
124
+
- track the most recent commit `rev` they have successfully processed
125
+
- keep cached identity data, and use cache expiration to ensure periodic re-validation of that data
126
+
- track account status
127
+
128
+
Identity caches should be purged any time an `#identity` event is received. Additionally, identity resolution should be refreshed if a commit signature fails to verify, in case the signing key was updated but the identity cache has not been updated yet.
129
+
130
+
When `tooBig` events are emitted on the firehose, downstream services will need to fetch the diff out-of-band. This usually means an API request to the `com.atproto.sync.getRepo` endpoint on the current PDS host for the account, with the `since` field included. The `since` value should be the most recently processed `rev` value for the account, which may or may not match the `since` field in the commit event message.
131
+
132
+
If a `#commit` is received with a `since` that does not match the most recently processed `rev` for the account, and is “later” (higher value) than the most recent commit `rev` the service has processed for that account, the service may need to do the same kind of out-of-band fetch as for a `tooBig` event.
133
+
134
+
Services should keep track of the `seq` number of their upstream subscriptions. This should be stored separately per-upstream, even if there is only a single Relay connection, in case a different Relay is subscribed to in the future (which will have different `seq` numbers).
135
+
136
+
Events can be processed concurrently, but they should be processed sequentially in-order for any given account. This can be accomplished by partitioning multiple workers using the repo DID as a partitioning key.
137
+
138
+
Services can confirm that they are consuming content reliably by fetching a snapshot of repository DIDs and `rev` numbers from other services, including PDS hosts and Relay instances. After a short delay, these can be compared against the current state of the service to identify any accounts which have lower than expected `rev` numbers. These repos can then be updated out-of-band.
139
+
140
+
The firehose can be used to follow new data updates, and repo exports can be used for snapshots. Actually combining the two to bootstrap a complete live-updating mirror can be a bit tricky. One approach is described below.
141
+
142
+
Keep a sync status table for all accounts (DIDs) encountered. The status can be:
143
+
144
+
- `dirty`: there is either no local repo data for this account, or it has gotten out of sync
145
+
- `in-process`: the repo is "dirty", but there is a background task in process to update it
146
+
- `synchronized`: a complete copy of the repository has been processed
147
+
148
+
Start by subscribing to the full firehose. If there is no existing repository data for the account, mark the account as "dirty". When new events come in for a repo, the behavior depends on the repo state. If it is "dirty", the event is ignored. If the state is "synchronized", the event is immediately processed as an update to the repo. If the state is "in-process", the event is enqueued locally.
149
+
150
+
Have a set of background workers start processing "dirty" repos. First they mark the status as `in-process`, so that new events are enqueued locally. Then the full repo export (CAR file) is fetched from the PDS and processed in full. The commit `rev` of the repo export is noted. When the full repo import is complete, the worker can start processing any enqueued events, in order, skipping any with a `rev` lower than the existing repo processed `rev` (as is the usual behavior). When the queue for the account is fully processed, the state can be flipped to `synchronized`, and the worker can move on.
151
+
152
+
After some time, most of the known accounts will be marked as `synchronized`, though this will only represent the most recently active accounts in the network. Next a more complete set of repositories in the network can be fetched, for example using an API query against an existing large service. Any new identified accounts can be marked as `dirty` in the service, and the background workers can start processing them.
153
+
154
+
When all of the accounts are `synchronized`, the process is complete. At large scale it may be hard to get perfect synchronization: PDS instances may be down at various times, identities may fail to resolve, or invalid events, data, or signatures may end up in the network.
155
+
156
+
Guidelines for specific firehose event sequencing during different account events are described in an [Account Lifecycle Best Practices guide](https://atproto.com/guides/account-lifecycle).
157
+
158
+
General mitigations for resource exhaustion attacks are recommended: event rate-limits, data quotas per account, limits on data object sizes and deserialized data complexity, etc.
159
+
160
+
Care should always be taken when making network requests to unknown or untrusted hosts, especially when the network locators for those host from from untrusted input. This includes validating URLs to not connect to local or internal hosts (including via HTTP redirects), avoiding SSRF in browser contexts, etc.
161
+
162
+
To prevent traffic amplification attacks, outbound network requests should be rate-limited by host. For example, identity resolution requests when consuming from the firehose, including DNS TXT traffic volume and DID resolution requests.
163
+
164
+
The `subscribeRepos` Lexicon is likely to be tweaked, with deprecated fields removed, even if this breaks Lexicon evolution rules.
165
+
166
+
The event stream sequence/cursor scheme may be iterated on to support sharding, timestamp-based resumption, and easier failover between independent instances.
167
+
168
+
Alternatives to the full authenticated firehose may be added to the protocol. For example, simple JSON serialization, filtering by record collection type, omitting MST nodes, and other changes which would simplify development and reduce resource consumption for use-cases where full authentication is not necessary or desired.